
CS106L
CS106L
Types and Structs
cpp的命令行编译方法:
$ g++ main.cpp -o main # g++ is the complier, outputs binary to main |
cpp和java一样,都是静态类型的语言,变量一旦被声明,就不能修改其类型。
(int) x将
x转换为int类型,去除浮点数部分。
结构体初始化方法:假设定义了一个StanfordID,拥有三个内置变量:name,sunet,idNumber。
使用的就是列表式初始化。
StanfordID yrb = {"1", "2", 3}; |
pair模板:
template<typename T1, typename T2> |
需要使用#include<utility>。
using可以用于对类型进行缩写。如:
using zeros = std::pair<double, double>; |
auto关键字可以让编译器自动推导类型,如:
auto result = solveProblem(a, b, c); |
但是注意auto还是静态类型的,下面的操作是非法的:
auto i = 1; |
Initialization and References
推荐:在声明一个变量时对其进行初始化。
直接初始化:
cpp在进行直接初始化时”不会进行类型检查“(实际上是进行了隐式类型转换)。例子如下:
int numOne = 12.0; |
使用这种方法可能会导致数据发生narrowing conversion,损失精度。
统一初始化:
int numOne{12.0} |
这种情况下:编译器会报错,提示double cannot be narrowed to int in initializer list。
修改方法为:
int numOne{12} |
统一初始化更加安全,因为不允许进行narrowing conversions,这是一种通用的方法。
在 C++17 中,结构化绑定(Structured Binding) 是一种便捷的语法,用于将结构体、数组或元组类型的多个成员解构到各个变量中,方便访问每个元素的值或进行解构赋值。
基本语法
结构化绑定使用 auto 关键字进行解构,并通过大括号
{} 来表示多个绑定变量:
auto [var1, var2, var3] = expression; |
其中 expression
必须是一个支持解构的类型,比如元组、数组、结构体等。
使用场景
解构
std::pair或std::tuple:这是结构化绑定最常见的用法,特别是用于 STL 容器中返回pair的情况。
int main() {
std::tuple<int, double, std::string> data = {42, 3.14, "Hello"};
auto [x, y, z] = data; // x -> 42, y -> 3.14, z -> "Hello"
std::cout << x << ", " << y << ", " << z << std::endl;
return 0;
}解构
std::map的迭代器:在遍历std::map时,可以直接解构键和值。
int main() {
std::map<int, std::string> map = {{1, "One"}, {2, "Two"}};
for (const auto& [key, value] : map) {
std::cout << key << ": " << value << std::endl;
}
return 0;
}解构结构体:如果一个结构体的所有成员都是公共的,或者是
public的struct,可以直接用结构化绑定解构它的成员。
struct Point {
int x;
int y;
};
int main() {
Point p = {10, 20};
auto [x, y] = p; // x -> 10, y -> 20
std::cout << "x: " << x << ", y: " << y << std::endl;
return 0;
}解构数组:可以用于定长数组,便于直接获得每个元素。
int arr[3] = {1, 2, 3};
auto [a, b, c] = arr; // a -> 1, b -> 2, c -> 3
注意事项
- 结构化绑定只适用于支持解构的类型(如数组、元组、
std::pair、struct等)。 - 在结构体上使用时,成员必须是公共的且支持解构。
- 绑定变量会是常量或引用,如果原类型是
const或&类型,解构出的变量会保留这些修饰符。
优点
- 提高了代码可读性和简洁性。
- 避免了手动解引用和访问成员,直接从容器或复合类型中获取多个值。
引用:需要注意下面一个点:
void shift(std::vector<pair<int,int>> &nums) |
虽然是按照值传递,但是我们没有对nums进行修改。
如果要进行修改,正确的方法如下:
void shift(std::vector<pair<int,int>> &nums) |
引用只能用于左值!!!
左值和右值:
左值:一个左值既可以在表达式左边也可以在表达式右边。
右值:只能在表达式右边,可以理解为其是”暂时的“。暂时的变量不可以被引用。
如:
int y = x; //allowed |
const限定符:
限制数据类型无法进行修改:
std::vector<int> vec{ 1, 2, 3 }; /// a normal vector |
可以发现:如果原来的对象限定为const,我们无法进行修改。
下面的操作也是非法的:
/// a const vector |
编译cpp程序:
以下是使用g++进行程序编译:
$ g++ -std::c++20 main.cpp -o main |
g++:编译器命令。-std::c++20:指定cpp版本。main.cpp:指的是源文件。-o:对可执行文件指定具体的名称。main:在这里是main。
Streams
cerr:用于输出错误。
clog:用于非关键事件日志记录。
cout:标准输出流。
cin:标准输入流。
stringstream
有两种初始化的方法:一种是构造函数初始化,另外一种是
<< 初始化。
注意是以\n为字符串的结尾。
e.g:
std::string initial_quote = "Bjarne Stroustrup C makes it easy to shoot yourself in the foot"; |
istream& getline(istream& is, string& str, char delim)
getline函数的定义:它接受三个参数:istream& is:输入流,比如cin或者文件输入流。string& str:用于存储读取内容的字符串。char delim:自定义的分隔字符,getline会读取内容直到遇到这个字符才停止。
getline()读取输入流is,直到遇到delim字符,并将内容存储到str中。
getline函数会从输入流is读取内容,遇到分隔字符delim时停止,然后将读取到的内容存储在str中。默认情况下,分隔字符
delim是换行符\n。
如果不指定delim,默认分隔字符是换行符\n,也就是说getline会读取一行内容直到换行。getline会忽略这个分隔符delim,不会将其存储到目标字符串中str。
在输出流中,字符会首先被存储在一个中间缓冲区中,然后再传送到最终的输出目标(例如,控制台或文件)。这个缓冲区的作用是提高输出效率,因为直接对输出设备(如硬盘或屏幕)写操作的代价较高。
具体解释如下:
缓冲区的概念:
当我们将数据写入输出流(例如std::cout)时,数据并不会立刻显示在屏幕上。取而代之的是,数据会先存放在内存中的一个缓冲区中。缓冲区的作用:
缓冲区可以暂时存储多个字符,这样可以一次性将这些数据输出,减少实际输出操作的次数,从而提升程序的运行效率。Flush(刷新)缓冲区:
缓冲区会在特定的情况下自动刷新,将数据发送到最终的目的地。例如:- 程序执行
std::endl或调用.flush()方法。 - 缓冲区满了,达到系统设置的容量上限。
- 程序正常结束时,缓冲区会被强制刷新。
- 程序执行
示例
|
在这个示例中,如果不使用 std::endl 或
flush,那么 "Hello"
可能会等到程序结束时才被输出,因为它在缓冲区中等待输出操作。
std::endl还有告诉输出流该行输出硬件结束的功能,同时告诉streams进行flush。
flush不会执行换行的功能。

这段文字讨论了 C++中的标准输出缓冲刷新机制,尤其是
'\n'换行符与std::cout之间的关系。主要意思是:
- 在很多 C++实现中,标准输出(例如
std::cout)是行缓冲的,这意味着当遇到'\n'时会自动刷新缓冲区(即输出到终端)。- 除非显式调用
std::ios::sync_with_stdio(false)禁用与 C 标准输入输出的同步,否则大多数情况下,'\n'会像std::endl一样刷新缓冲区。- 这意味着
'\n'和std::endl在大多数情况下效果类似,都会导致输出刷新到屏幕上。- 但是,在文件输出中,
'\n'不会立即刷新缓冲区,这与标准输出的行为有所不同。总结来说,
'\n'在标准输出时会刷新缓冲区,而在文件输出中则不会,这种行为可以通过std::ios::sync_with_stdio(false)进行控制。
缓冲区的作用:
缓冲区的主要作用是提高性能。当程序输出数据时,缓冲区会临时存储这些数据,等到满足一定条件(比如缓冲区满了,或遇到换行符)时,才将数据一次性输出到目标(如屏幕、文件、网络等)。这减少了 I/O 操作的次数,从而提高了程序的运行效率。
以下是缓冲区的作用和刷新缓冲区对性能的影响:
减少 I/O 操作次数:每次 I/O 操作都会耗费系统资源,尤其是涉及磁盘或网络的操作。通过缓冲区,可以将多次小规模的 I/O 操作合并为一次大规模的 I/O 操作,显著减少系统调用的次数,从而提高性能。
提高数据传输效率:例如,向磁盘写入数据时,每次写入都有一定的开销。如果每次输出一个字符或少量数据,开销会很大。而使用缓冲区,可以等积累了一批数据后再统一写入,这样速度更快。
自动刷新机制:在某些情况下,程序会自动刷新缓冲区,比如遇到换行符(在行缓冲模式下)或程序结束时。这使得输出数据更灵活,用户在需要实时查看输出时可以使用手动刷新(如
std::endl或std::flush),而在不需要时可以依赖缓冲区延迟输出以提高性能。刷新缓冲区的代价
虽然刷新缓冲区能让数据立即显示出来,但频繁刷新会影响性能,尤其是在循环中频繁输出时。例如,以下代码会导致多次刷新:
std::cout << i << std::endl; // 每次迭代都刷新缓冲区
}这会比以下代码效率低得多:
std::cout << i << "\n"; // 缓冲区满了才刷新,减少了刷新次数
}
std::cout << std::flush; // 只在需要时手动刷新总结
缓冲区通过减少 I/O 操作次数来提升性能,而刷新缓冲区会影响性能。在实时性要求不高的情况下,利用缓冲区延迟输出是提升程序效率的重要手段。
C++
在一些情况下会自动刷新(flush)输出缓冲区,而不需要程序员手动调用
std::flush 或 std::endl
来刷新。这是因为 C++
的标准库会在特定条件下自动触发缓冲区的刷新,将缓冲区中的数据输出到终端或文件中。
自动刷新(Auto Flush)的情况
C++ 会在以下几种情况自动刷新输出缓冲区:
输出换行符
std::endl
当使用std::endl时,它不仅会输出换行符,还会自动刷新缓冲区。std::cout << "Hello" << std::endl; // 输出 "Hello" 并自动刷新
程序正常结束时
在main函数结束时,C++ 会自动刷新所有缓冲区,确保所有输出都被显示或保存。输入流和输出流交替使用时
当输入和输出流(如std::cin和std::cout)交替使用时,C++ 会自动刷新输出缓冲区。例如:std::cout << "Enter a number: "; // 自动刷新,使提示信息立即显示
int num;
std::cin >> num;缓冲区满时
如果缓冲区中的数据达到了系统设定的上限,C++ 会自动刷新缓冲区,确保数据被输出。
总结
C++ 的输出流在这些场景下会自动刷新,确保重要信息及时输出,而不需要程序员显式地进行缓冲区管理。
std::stringstream是 C++ 标准库中的一个类,用于将字符串和其他类型的数据相互转换,同时提供类似流(std::cin、std::cout)的接口来操作字符串数据。它在处理格式化字符串和数据转换时非常有用,例如从字符串中提取数值或将数值转换成字符串。基本用法
std::stringstream位于<sstream>头文件中,可以通过以下方式包含:
常用的
stringstream相关类有:
std::istringstream:从字符串中读取数据。std::ostringstream:向字符串中写入数据。std::stringstream:既能读取又能写入字符串。常见操作
- 初始化与写入
std::stringstream可以通过构造函数直接初始化字符串或调用<<操作符进行写入。
int main() {
std::stringstream ss; // 创建一个 stringstream 对象
ss << "Hello, " << 42; // 向流中写入字符串和整数
std::cout << ss.str(); // 输出整个字符串流内容
return 0;
}输出:
- 从字符串读取
可以使用
>>操作符从std::stringstream中读取数据,并支持自动的类型转换。
int main() {
std::string str = "100 3.14 Hello";
std::stringstream ss(str);
int i;
double d;
std::string word;
ss >> i >> d >> word; // 从流中读取整数、浮点数和字符串
std::cout << "Integer: " << i << ", Double: " << d << ", String: " << word << std::endl;
return 0;
}输出:
- 数据转换
std::stringstream常用于数据转换,比如将数值转换为字符串,或从字符串中解析出数值。
数值转字符串
std::stringstream ss;
ss << number;
std::string str = ss.str(); // 获取流中的字符串
std::cout << "String: " << str << std::endl;字符串转数值
std::stringstream ss(str);
int number;
ss >> number;
std::cout << "Number: " << number << std::endl;
- 清除流内容
可以通过调用
.str("")清空流内容,或通过.clear()清除错误标志以便重新使用。
ss << 100;
ss.str(""); // 清空流内容
ss.clear(); // 清除错误标志优点
- 便捷的数据转换:通过流的方式自动处理格式化。
- 高效读取:可以逐个提取不同类型的数据,简化从字符串中提取信息的过程。
注意事项
- 使用
>>读取数据时,如果流中内容与预期数据类型不匹配,可能会导致读取失败,需要检查并处理流的状态。
下面是文件输入输出流:
testFstream函数通常用于测试 C++中的文件流操作,即使用std::fstream对象进行文件的读写操作。fstream类位于<fstream>头文件中,提供了处理文件输入输出的功能。以下是一个示例代码,展示了testFstream函数如何执行基本的文件读写操作:
void testFstream() {
std::fstream file;
// 打开文件进行读写操作(如果文件不存在则创建它)
file.open("example.txt", std::ios::in | std::ios::out | std::ios::trunc);
if (!file) {
std::cerr << "文件无法打开!" << std::endl;
return;
}
// 写入文件
file << "Hello, world!" << std::endl;
file << "This is a test for fstream." << std::endl;
// 将文件指针重新定位到文件开头
file.seekg(0);
// 读取文件内容
std::string line;
while (std::getline(file, line)) {
std::cout << line << std::endl;
}
// 关闭文件
file.close();
}
int main() {
testFstream();
return 0;
}代码解释
- 打开文件:
file.open("example.txt", std::ios::in | std::ios::out | std::ios::trunc);打开文件example.txt进行读写。如果文件不存在,将创建该文件,std::ios::trunc表示打开时会清空已有内容。- 写入文件:使用
file << "text"将内容写入文件。- 重定位文件指针:通过
file.seekg(0)将读取指针移动到文件开头,以便接下来可以读取刚刚写入的内容。- 读取文件:通过
std::getline(file, line)逐行读取文件内容并输出到控制台。- 关闭文件:使用
file.close()关闭文件,释放资源。
testFstream函数展示了文件流的基本操作,适用于需要文件读写的简单场景。
std::cin
是一个缓存,可视作一个用户暂时存储数据,然后再从其中读取的地方。
它将会在遇到空白符是停止:空白符指" ",\n,\t。
int main() { |
如果是合法的输入,和理想情况一样。
如果是非法的输入,就比较有趣了:
3.14 xxx yyy 222 |
这是因为在cin在读取到空白符时就会停止。
为什么tao会是 0?
当输入
tao时,由于输入yyy无法被解析为double类型,std::cin >> tao操作失败,导致流进入“错误状态”。在这种情况下,std::cin会默认保留tao变量的原始值,或者初始化值。在你的代码中,tao原本被初始化为12,但在 C++中,当流读取失败时,未成功写入的变量通常保持默认的值。这里,流的错误会将未读取的变量视作无效,使得tao的值被保留为0(即初始化失败的情况下,它无法保留原本预设的数值12)。在这种错误状态中:
- 变量
tao无法获得新值;- 因错误状态未清除,变量内容被保留为
0。为解决此问题,可以在错误检测后重设变量,清除流错误状态并重新输入
修改方法:
int main() { |
getline这里默认遇到\n停止读取。
注意不要一起使用std::getline和std::cin,除非迫不得已。
Containers
解决如何存储组织数据的问题。
建议:使用基于范围的迭代,可以适用于所有可以迭代的容器。
for (auto ele: vec){ |
建议:使用const auto&,可以比减少潜在的对每个元素的复制花费。
for (const auto& elem: v) |
运算符[]没有提供下边检查。
Zero overhead(零开销)是 C++ 语言设计中的一个重要理念,指的是在使用高级特性时不会增加额外的运行时开销。这意味着当你在 C++ 中使用更抽象的、高级的语言特性(如模板、RAII、智能指针等)来编写代码时,这些特性不会比直接用低级代码写的等价代码更慢。换句话说,如果一种高级特性可以被优化为零开销,那么编译器就会尽量实现这种优化。
具体含义
抽象无开销:高级特性如模板、类和运算符重载等,编译器会尽量将它们优化成零开销。这种情况下,使用这些抽象的代码的性能会与直接写底层代码(比如直接使用函数指针或普通的循环)相同。例如,模板编程会被编译器实例化为具体类型的代码,避免了运行时的多态开销。
编译器优化:C++ 编译器会对代码进行优化,剔除不必要的开销。例如,在使用
std::vector等标准容器时,编译器会优化掉没有用到的边界检查和迭代器检查,使其性能接近于原生数组。不使用即不付费:C++ 的零开销哲学还包括“不使用即不付费”(you don’t pay for what you don’t use)。如果你没有使用某个功能或特性,它不会给程序带来任何额外的开销。这样设计的目的是让程序员在追求性能时,可以更灵活地选择需要的特性。
实例
1. 模板的零开销
模板可以为每个具体类型生成特定代码,避免了运行时的多态性开销:
T add(T a, T b) {
return a + b;
}
int main() {
int result = add(1, 2); // 模板实例化后,相当于直接调用 int add(int, int)
}在这个例子中,模板在编译期实例化,不会有运行时的额外开销。
2. RAII 的零开销
RAII(Resource Acquisition Is Initialization)利用构造和析构函数自动管理资源,使得资源管理代码不会带来额外的运行时开销:
int main() {
std::unique_ptr<int> ptr = std::make_unique<int>(42); // 智能指针自动管理内存
std::cout << *ptr << std::endl;
} // 离开作用域后,内存自动释放通过 RAII 方式管理内存,不会增加运行时开销,而且比手动管理更安全。
总结
“Zero overhead” 是 C++ 的设计哲学之一,允许程序员在使用高级特性和抽象时,仍然能够写出高性能、接近底层实现的代码。这种设计平衡了代码的抽象度和运行效率,使得 C++ 在系统编程领域中被广泛使用。
deque拥有和vector一样的接口,除此之外,还有push_front,pop_front。
vector分配的内存空间是一块连续的内存,而deque底层分配的内存是不连续的内存块。
分别对应的是vector,deque,map,unordered_map。
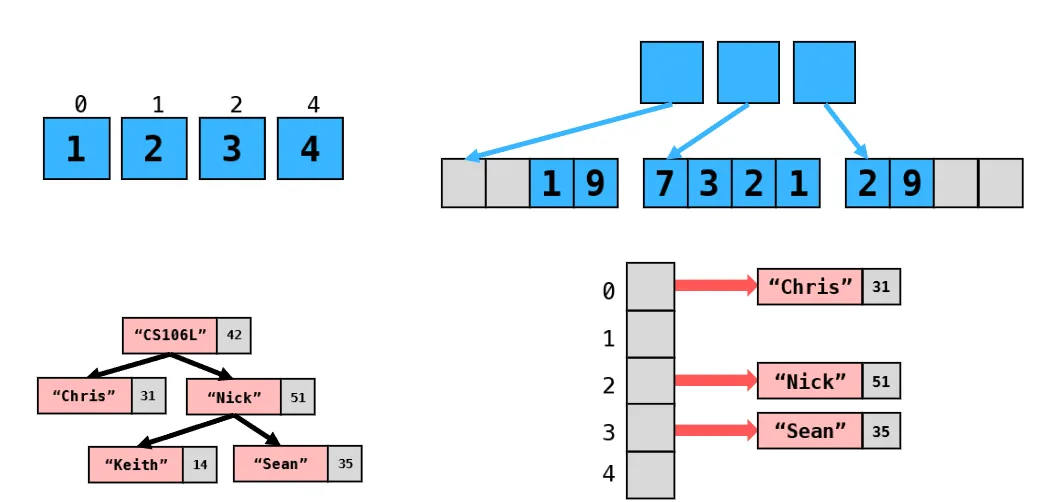
在
std::map<K, V>中,键K是常量类型 (const) 的原因是为了确保映射的键一旦插入后便不会被修改。这样设计有助于保持映射的有序性和数据完整性。具体原因包括以下几点:1. 保持键的不可变性
std::map是一种基于有序树结构(如红黑树)实现的容器,插入元素时会按照键值进行排序。为了保持这种有序性,键一旦插入就必须保持不变,否则改变键的值会破坏原有的排序结构,从而影响map的查找、插入和删除操作。2. 避免误操作
在
map中,如果允许修改键,会导致潜在的误操作风险。例如,假设允许修改键,则可能在无意中修改了一个键值,导致该元素不再位于正确的有序位置,甚至可能造成重复键的存在。将键设置为const后,编译器会直接禁止对键的修改,防止这些问题的出现。3. 保证高效查找
std::map使用平衡树结构来进行键的查找、插入和删除操作,而平衡树的高效查找依赖于键的有序性。键被修改后会影响查找路径,导致效率下降或查找错误。因此,通过将键定义为const,可以确保map中的每个键都处于正确的有序位置,从而保持高效的查找性能。示例
例如,如果
map中的键不为const,以下代码可能会带来问题:
int main() {
std::map<int, std::string> myMap = {{1, "one"}, {2, "two"}};
auto it = myMap.find(1);
// 假设可以修改键:*it.first = 3; // 编译错误
std::cout << it->first << ": " << it->second << std::endl;
}将键设为
const后,it->first是不可修改的,编译器会阻止不合法的操作,确保每个键值对的有序性。
map可以视作pair的一种集合。
map也可以适用于结构化绑定。
注意map<K,V>需要K拥有一个<,也就是说,可以进行排序。
//ok |
是的,
map["A"] = 0会将键"A"插入到map中(如果"A"不存在的话)。这是因为std::map的operator[]在使用时会有以下行为:
如果键不存在:
map["A"]会创建一个新的键值对,其中键为"A",并使用V类型的默认构造值(对整数类型来说是0)初始化其值。然后map["A"] = 0将值设置为0,即使默认值也是0,操作仍然会执行。如果键已经存在:
map["A"]将直接返回键"A"对应的值,然后将其赋值为0。示例
int main() {
std::map<std::string, int> myMap;
myMap["A"] = 0; // "A" 不存在时,会插入键值对 {"A", 0}
std::cout << "myMap['A']: " << myMap["A"] << std::endl; // 输出 0
std::cout << "Map size: " << myMap.size() << std::endl; // 输出 1,表示有一个元素被插入
return 0;
}输出:
Map size: 1注意
- 使用
map[key]会在键不存在时创建该键并初始化值,所以如果只是想检查键是否存在而不插入键,可以使用map.find("A"),它不会修改map的内容。
set存储的是一组唯一的元素,意思是set容器中的每个元素都是独一无二的,不允许重复。这意味着如果试图将已经存在的元素再次插入到set中,插入操作将会被忽略,不会改变set的内容。在 C++ 中,
std::set是一个有序集合,内部通过某种排序机制(通常是红黑树)实现的,因此所有元素也会按照顺序存储。特性总结
- 唯一性:
set自动确保所有元素的唯一性,插入重复元素时会被忽略。- 有序性(对于
std::set):
- 元素按照升序(默认)或指定的排序规则排列。
- 插入元素后,不需要手动排序,
set会自动调整顺序。示例
int main() {
std::set<int> mySet;
mySet.insert(10);
mySet.insert(20);
mySet.insert(10); // 10 已经存在,不会插入
for (int item : mySet) {
std::cout << item << " ";
}
return 0;
}输出:
在这个例子中,尽管
10被插入了两次,set只保留一个10,确保所有元素唯一。
map和set基本上都有以下功能:
insert(k); //插入k map中为insert({k, v}) |
map is a collection of std::pair, unordered_map stores a collection of n "buckets" of pairs 什么意思
这句话的意思是:
map是std::pair的集合:在std::map中,每个元素都是一个键值对(std::pair<Key, Value>),并且这些键值对是按键的顺序排列的。例如,在std::map<int, std::string>中,每个元素都是一个std::pair<int, std::string>,代表键和对应的值。std::map使用平衡树结构(如红黑树)实现,保证键值对按顺序存储,且插入、删除和查找操作的时间复杂度为 (O(n))。
unordered_map存储的是一组“桶”的集合:std::unordered_map不按键的顺序存储,而是将元素放入一个由多个“桶”构成的集合中,每个桶可以存放多个键值对。桶的位置是通过哈希函数计算得到的。对于每个键值对,unordered_map根据键的哈希值选择桶,然后将键值对存储在该桶中。这种实现方式使得unordered_map的查找、插入和删除的平均时间复杂度为 (O(1))。具体上:就是将键值通过哈希函数进行计算,得到哈希值,最后
mod桶的数目,得到确定的要插入的桶。后续猜测可能是使用像链表的方法进行实现。
具体区别
std::map:有序映射,存储的键值对集合是有序的,每个键值对是一个std::pair,键具有唯一性,适合需要按顺序遍历键值对的场景。std::unordered_map:无序映射,键值对存放在哈希桶中,根据哈希值查找,键具有唯一性,适合快速查找键值对的场景,但键的顺序不固定。示例
int main() {
std::map<int, std::string> orderedMap;
orderedMap[3] = "three";
orderedMap[1] = "one";
orderedMap[2] = "two";
std::cout << "Ordered map:" << std::endl;
for (const auto& pair : orderedMap) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
std::unordered_map<int, std::string> unorderedMap;
unorderedMap[3] = "three";
unorderedMap[1] = "one";
unorderedMap[2] = "two";
std::cout << "\nUnordered map:" << std::endl;
for (const auto& pair : unorderedMap) {
std::cout << pair.first << ": " << pair.second << std::endl;
}
return 0;
}输出:
1: one
2: two
3: three
Unordered map:
3: three
1: one
2: two在
orderedMap中,键值对按顺序输出;而在unorderedMap中,键值对的顺序可能因哈希函数而有所不同。
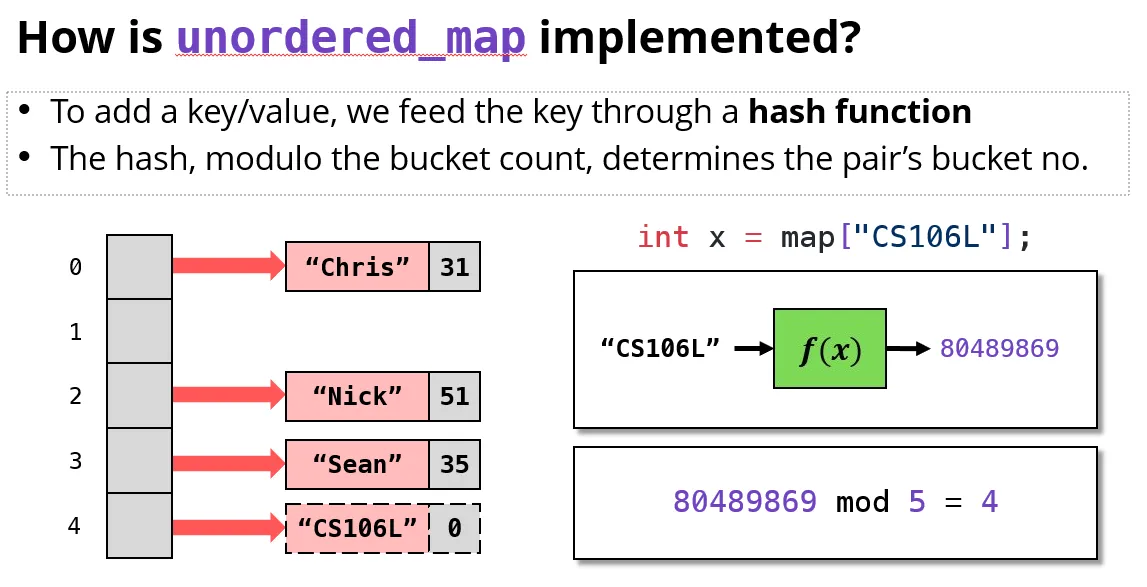
What is a hash function?
- “Scrambles" a key into a size t(64 bit)
- Small changes in the input should produce large changes in the output
哈希函数是一种算法,它接受一个输入(例如一个键)并生成一个固定大小的字节串,通常用整数表示。在数据结构(如哈希表)中,哈希函数的作用是将数据映射到内存中的一个位置(例如
unordered_map中的某个“桶”)。哈希函数的目标是尽可能让不同的输入映射到不同的位置,以减少“冲突”。在这段描述中:
“将键‘扰乱’成一个 64 位的
size_t”:哈希函数会将输入(如字符串或整数)转换为一个固定大小的 64 位值。这里的“扰乱”意味着哈希函数会使输出看起来像是随机的,以确保即使输入值相似,输出也会非常不同。“输入的微小变化应在输出中产生巨大的变化”:这是一个重要特性,叫做雪崩效应。如果输入稍微变化(比如从
"key1"变成"key2"),哈希值应该产生显著的差异。这有助于减少相似输入产生相同哈希值的几率,从而更均匀地分布数据。
How is unordered map implemented?
- lf two keys hash to the same bucket, we get a hash collision
- During lookup, we loop through bucket and check key equality
- Two keys with the same hash are not necessarily equal!
在
unordered_map中:
“如果两个键的哈希值映射到同一个桶,就会产生哈希冲突”:
unordered_map使用哈希函数将每个键分配到一个“桶”中。当两个不同的键产生相同的哈希值并指向同一个桶时,就会发生哈希冲突。“在查找时,我们遍历桶并检查键是否相等”:当
unordered_map查找元素时,首先通过哈希值确定键所在的桶。如果该桶中有多个键值对(因为冲突),就会遍历该桶中的每个键,并检查它们是否与要查找的键相等。“两个具有相同哈希值的键不一定相等!”:这句话强调,即使两个不同的键可能产生相同的哈希值(造成冲突),但它们不一定是相等的。只有在通过
==检查确认键相等时,才会认为它们是相同的,而不是仅仅因为它们的哈希值一样。这个机制让
unordered_map可以通过“链式存储”来处理冲突,在同一个桶中存放多个元素,并通过检查键的相等性来区分不同的元素。
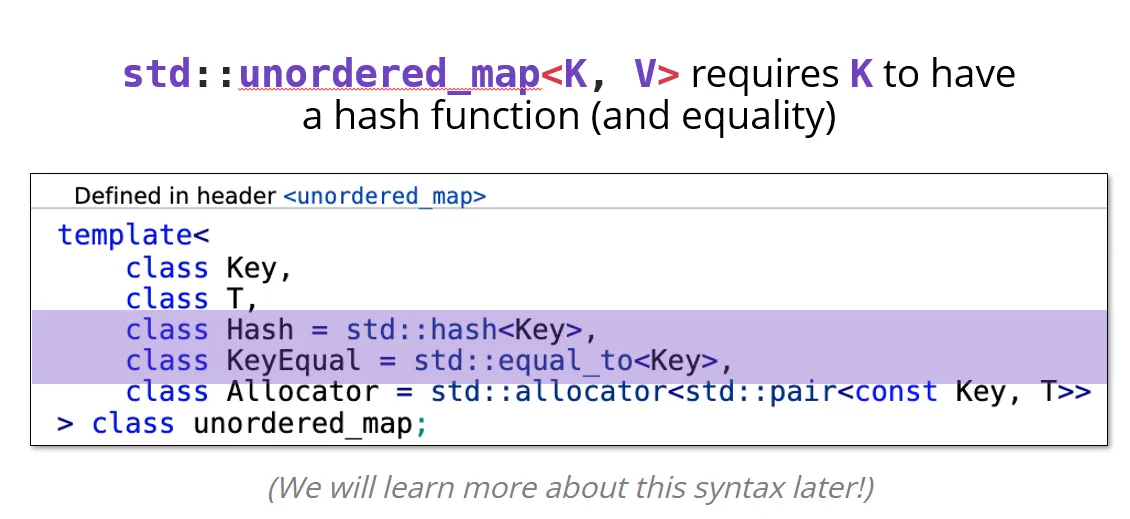
存疑?
unordered_map<K,V>需要K可以进行哈希操作,如:
std::unordered_map<int, int> map1; //ok string double int is ok |
Why use std::unordered map?
- Load factor: average number items per bucket
- unorderedmap allows super fast lookup by keeping load factor small
- If load factor gets too large (above 1.0 by default), we rehash
使用
std::unordered_map的原因包括:
加载因子(Load Factor):
load factor是指平均每个桶中的元素数量。std::unordered_map使用哈希表存储数据,如果负载因子较低,每个桶中就会有较少的元素,查找速度会更快。保持较低的加载因子可以减少哈希冲突,确保查找操作的效率。超快速查找:由于
std::unordered_map使用哈希表来存储数据,通常可以在 常数时间复杂度 (O(1)) 下完成查找操作。保持较低的加载因子可以帮助实现这一点。重新哈希(rehash):当加载因子变得过大(通常超过 1.0),即桶中平均有一个以上的元素时,
unordered_map会自动重新哈希,也就是增加桶的数量并重新分配所有元素,以降低加载因子。这能让查找效率维持在理想状态。示例:
int main() {
std::unordered_map<int, std::string> myMap;
// 插入一些元素
myMap[1] = "one";
myMap[2] = "two";
myMap[3] = "three";
// 输出加载因子
std::cout << "Load factor: " << myMap.load_factor() << std::endl;
return 0;
}在这个例子中,我们可以看到当前的加载因子,
unordered_map会根据它动态调整桶的数量,以保持快速查找。
可以设置unordered_map的load_factor,确保在超过某个上限后重新进行哈希。
std::unordered_map<string, int> map; |
unorder_set不用再介绍了,可以类比map和unordered_map的关系。
使用建议:
When to use unordered map vs. map?
- unordered map is usually faster than map
- However, it uses more memory(organized vs. disorganized garage)
- lf your key type has no total order (operator<), use unordered_map!
- lf you must choose, unordered map is a safe bet
可以拓展一下:array,list,multiset,multimap。
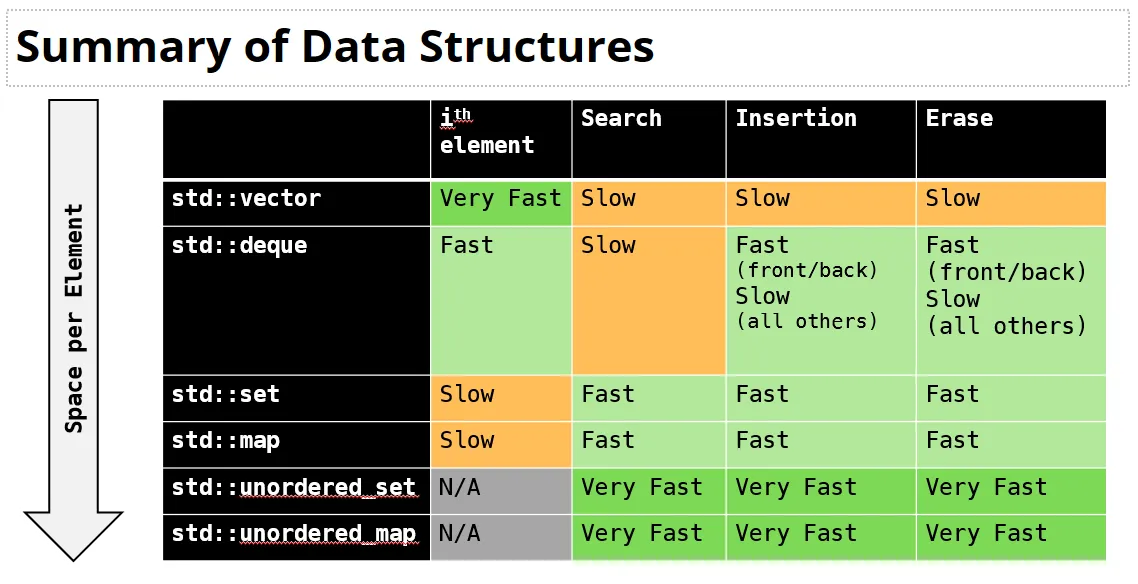
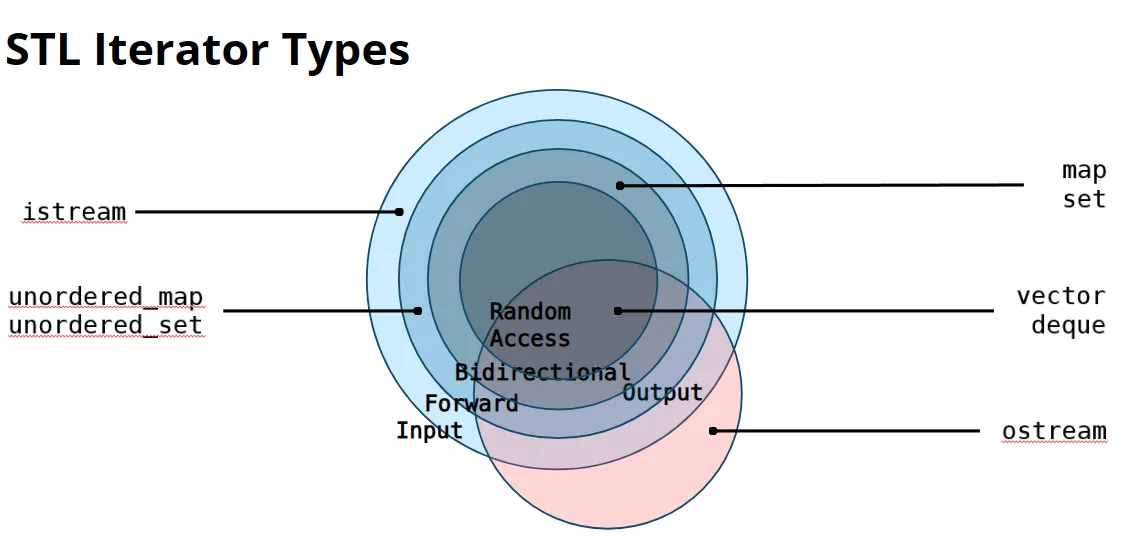
Iterators
研究如何遍历容器。
Container interface
container begin()
- Gets an iterator to the first element of the container(assuming non-empty)
container.end()
- Gets a past-the-end iterator
- That is,an iterator to one element after the end of the container
注意:end()没有指向任何一个元素。指向的是最后一个元素的后一个位置。
如果容器时空的,那么start()==end()。
基本四件套:
auto it = c.begin(); //copy construction |
使用auto it = m.begin(),这样可以避免iteerator types的过长拼写。
std::map<int,int>::iterator it = m.begin(); |
拓展升级:部分迭代器有:
--it; //move backwoards |
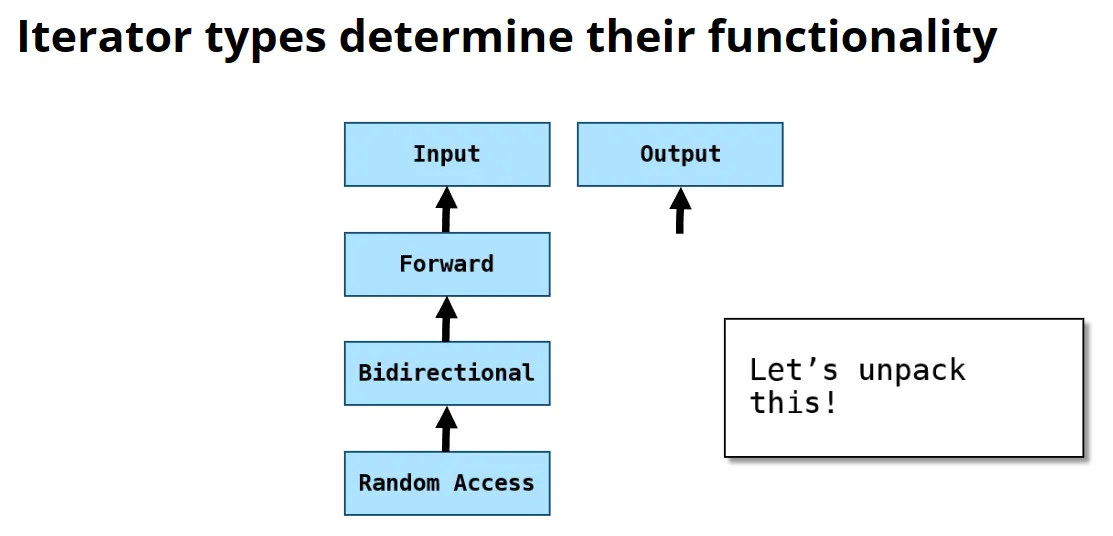
Input:最基础的迭代器,允许读取元素。
auto elem = *it |
如果数据类型是struct,可以使用->访问元素。
auto it = v.begin(); |
Output:允许我们写元素。
*it = elem |
Forward:允许进行单向移动,遍历容器中的元素。但是不能后移。所有STL都支持该操作。
Forward Iterator 是一种迭代器类型,允许单向遍历容器中的元素。它的主要特点是可以向前移动,但不能向后移动。
主要特性:
单向遍历:Forward Iterator 只能向前移动,无法回退。你可以通过
++操作符移动到下一个元素,但不能使用--操作符。可读性:可以读取指向的元素的值。这意味着你可以使用解引用操作符
*来获取当前元素的值。可写性:一些 Forward Iterator 也支持写入操作(即可以修改所指向的元素),这取决于具体的迭代器实现。如果它是一个写入迭代器,那么你可以使用
*操作符进行赋值。多次使用:与其他迭代器相比,Forward Iterator 可以在不同的遍历中安全地使用,这意味着你可以在遍历过程中重新使用相同的迭代器。
示例
在 C++ 中,
std::forward_list使用 Forward Iterator。下面是一个简单的示例,演示如何使用 Forward Iterator 遍历一个容器:
int main() {
std::forward_list<int> myList = {1, 2, 3, 4, 5};
// 使用 Forward Iterator 遍历容器
for (auto it = myList.begin(); it != myList.end(); ++it) {
std::cout << *it << " ";
}
return 0;
}总结
Forward Iterator 是一种重要的迭代器类型,适用于需要单向访问的场景。它提供了一种简单而高效的方式来遍历容器中的元素。
Bidirectional:可以进行前移和后移。适用于map和set。
Bidirectional Iterator 是一种迭代器类型,允许双向遍历容器中的元素。它的主要特点是可以在前向和后向之间移动。
主要特性:
双向遍历:Bidirectional Iterator 可以使用
++操作符向前移动到下一个元素,也可以使用--操作符向后移动到前一个元素。这使得它比单向的 Forward Iterator 更灵活。可读性:可以读取指向的元素的值,可以使用解引用操作符
*来获取当前元素的值。可写性:一些 Bidirectional Iterator 也支持写入操作(即可以修改所指向的元素),这取决于具体的迭代器实现。
适用范围广:Bidirectional Iterator 通常用于支持双向遍历的容器,例如
std::list和std::set。示例
在 C++ 中,
std::list和std::set都使用 Bidirectional Iterator。下面是一个简单的示例,演示如何使用 Bidirectional Iterator 遍历一个std::list:
int main() {
std::list<int> myList = {1, 2, 3, 4, 5};
// 使用 Bidirectional Iterator 正向遍历容器
std::cout << "Forward traversal: ";
for (auto it = myList.begin(); it != myList.end(); ++it) {
std::cout << *it << " ";
}
std::cout << std::endl;
// 使用 Bidirectional Iterator 反向遍历容器
std::cout << "Backward traversal: ";
for (auto it = myList.end(); it != myList.begin();) {
--it; // 向前移动到前一个元素
std::cout << *it << " ";
}
return 0;
}输出
Backward traversal: 5 4 3 2 1总结
Bidirectional Iterator 是一种灵活的迭代器类型,支持双向遍历,适用于需要在容器中前后移动的场景。它提供了一种简便的方法来遍历和操作容器中的元素。
Random Access:可以快速的执行前移和后移。支持的有vector和deque。
Random Access Iterator 是一种迭代器类型,允许对容器中的元素进行随机访问。它提供了对容器元素的直接跳转,支持多种操作,使得用户可以非常灵活地访问和修改元素。
主要特性:
随机访问:可以使用整数偏移量来直接访问容器中的任意元素。例如,可以使用
it + n来访问距离当前迭代器n个位置的元素,或使用it[n]语法。支持算术运算:支持加法、减法等算术运算,例如
++、--、+和-操作符。这意味着你可以快速移动到前面或后面的元素。可读性:可以读取指向的元素的值,可以使用解引用操作符
*来获取当前元素的值。可写性:一些 Random Access Iterator 也支持写入操作,允许用户修改所指向的元素。
适用范围广:Random Access Iterator 通常用于支持快速随机访问的容器,例如
std::vector和std::deque。示例
在 C++ 中,
std::vector使用 Random Access Iterator。下面是一个简单的示例,演示如何使用 Random Access Iterator 访问一个std::vector中的元素:
int main() {
std::vector<int> myVector = {10, 20, 30, 40, 50};
// 使用 Random Access Iterator 访问元素
std::cout << "Accessing elements using Random Access Iterator:" << std::endl;
for (size_t i = 0; i < myVector.size(); ++i) {
std::cout << "Element at index " << i << ": " << myVector[i] << std::endl;
}
// 直接使用迭代器进行随机访问
auto it = myVector.begin();
std::cout << "Element at index 2: " << *(it + 2) << std::endl; // 访问第3个元素
return 0;
}输出
Element at index 0: 10
Element at index 1: 20
Element at index 2: 30
Element at index 3: 40
Element at index 4: 50
Element at index 2: 30总结
Random Access Iterator 是一种非常强大和灵活的迭代器类型,支持快速和随机地访问容器中的元素。它的高效性使其在需要频繁访问和修改数据的场景中非常有用。
使用迭代器时,注意不要越界。
iterator指向的容器中的元素。
pointer指向的是任何类。
Classes
析构函数是在对象离开其作用域时被自动调用的。
动态多态性(Dynamic Polymorphism):不同类型的对象可能会有相同的接口。
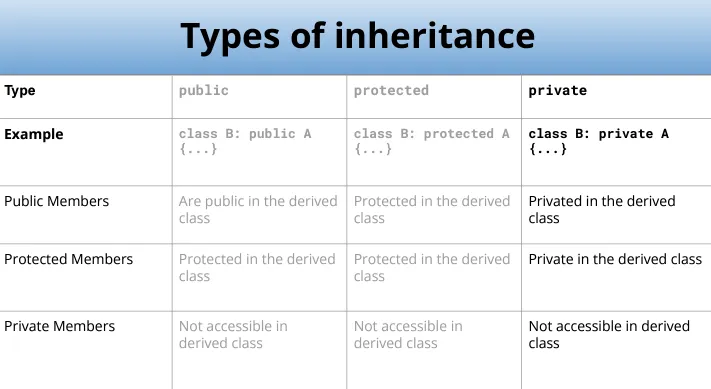
The constructor has all of the protected members.
虚继承(Virtual Inheritance) 是 C++ 中的一种特殊继承机制,用于解决多重继承时可能出现的菱形继承问题(Diamond Problem)。
菱形继承问题
在多重继承中,如果一个类同时继承了两个基类,而这两个基类又共同继承自同一个父类,可能会导致二义性。这种情况称为菱形继承。假设有以下类关系:
/ \
B C
\ /
D在这个示例中,类
B和C都从类A继承,而类D同时从类B和C继承。这样,D就会有两个A的实例,这就造成了歧义,D不能确定自己是通过B还是C继承的。虚继承的解决方案
通过使用虚继承,所有派生类可以共享同一个基类的实例,解决了菱形继承的问题。
使用虚继承的示例代码如下:
class A {
public:
A() { std::cout << "A's constructor" << std::endl; }
};
class B : virtual public A {
public:
B() { std::cout << "B's constructor" << std::endl; }
};
class C : virtual public A {
public:
C() { std::cout << "C's constructor" << std::endl; }
};
class D : public B, public C {
public:
D() { std::cout << "D's constructor" << std::endl; }
};
int main() {
D d; // 创建 D 的实例
return 0;
}输出
B's constructor
C's constructor
D's constructor解释
虚继承:在
B和C中使用virtual关键字继承A,意味着无论D继承自B还是C,它们都共享同一个A的实例。构造顺序:构造函数的调用顺序是:首先调用基类
A的构造函数,然后是B和C的构造函数,最后是D的构造函数。这样确保了基类的构造函数只会被调用一次,避免了二义性。总结
虚继承是 C++ 中处理多重继承中菱形继承问题的重要机制。它确保了在继承链中只存在一个基类实例,从而消除了潜在的歧义和不一致性。
Templates
在 C++ 中,模板和 Java 中的 泛型 处理类型的方式有所不同,这影响了类型不匹配时何时会报错。以下是两者的主要区别和错误发生的时机:
C++ 模板
实例化时:C++ 模板是在编译时进行实例化的。即当你使用某个模板类或模板函数时,编译器会生成相应的代码。因此,任何类型不匹配的错误都会在编译阶段被检测到。例如:
void func(T arg) {
// 可能会在这里使用 arg
}
int main() {
func(5); // 正确
func("Hello"); // 错误:不匹配的类型
return 0;
}在这个例子中,如果
func的参数类型与使用的类型不匹配,编译器会在编译时抛出错误。多态性:由于 C++ 的模板是编译时解析的,不能使用运行时类型信息。因此,不能在运行时进行类型检查。
Java 泛型
运行时检查:Java 的泛型在编译时是类型安全的,但在运行时,它们会被类型擦除(Type Erasure)。这意味着在编译阶段,泛型类型的信息会被移除,替换为原始类型。因此,泛型类型的类型不匹配通常会在编译时捕获,但某些情况下可能会在运行时引发错误。例如:
void func(T arg) {
// 可能会在这里使用 arg
}
}
public class Main {
public static void main(String[] args) {
GenericClass<Integer> gc = new GenericClass<>();
gc.func(5); // 正确
// gc.func("Hello"); // 编译错误:类型不匹配
}
}在这个例子中,尝试传递一个与泛型类型不匹配的参数会导致编译错误。
运行时类型错误:由于类型擦除,Java 在某些情况下可能会在运行时引发
ClassCastException,例如在使用原始类型时:
list.add("Hello");
String str = (String) list.get(0); // 正确
Integer num = (Integer) list.get(0); // 运行时错误:ClassCastException总结
- C++ 模板:错误在编译时发现,类型不匹配会导致编译错误。
- Java 泛型:大部分错误在编译时发现,但由于类型擦除,有时会在运行时发现类型不匹配的错误。
这使得 C++ 在使用模板时更具类型安全性,而 Java 的泛型提供了更好的灵活性和可读性,但需要注意运行时的类型问题。
推荐使用array而不是vector,因为避免了堆分配,已经知道确切的大小,从而进行堆栈分配。
下面是一些编写模板时的注意事项:
//Vector.h |
需要在
.cpp文件中加上template <typename T>。并且除此之外,对应的模板也需要加上<T>://error
template <typename T>
T& Vector::at(size_t i)
{
//code
}
//good
template <typename T>
T& Vector<T>::at(size_t i)
{
//code
}.h文件必须包含在.cpp文件的底部!!!
//normal |
//template |
在 C++ 中,当你实现模板类或模板函数时,通常会将声明放在
.h文件中,将定义(实现)放在.cpp文件中。然而,模板的一个特殊之处在于,它的实现代码需要在编译时被完全看到,因此在模板的.h文件中包含对应的.cpp文件是为了确保编译器可以看到模板的定义,以便正确生成实例化代码。原因详解
模板的编译机制:
- 在 C++ 中,模板的实现和实例化是在编译时完成的。编译器在看到模板定义时并不会立即生成代码,而是在模板被使用时才实例化。
- 因此,如果将模板的实现(定义)放在
.cpp文件中,编译器在编译头文件时无法看到具体实现,从而无法进行实例化,会导致链接错误。包含
.cpp文件的解决方法:
- 将模板的实现包含在头文件中,可以让编译器在每次需要时都能够“看到”实现细节,从而生成实例代码。
- 通过在模板的
.h文件末尾包含.cpp文件,等同于将实现直接写在头文件中,同时也能保持代码结构的清晰,将声明和实现分开。实际示例
假设有一个简单的模板类
MyTemplate:MyTemplate.h 文件:
template <typename T>
class MyTemplate {
public:
MyTemplate(T value);
T getValue() const;
private:
T value;
};
// 在头文件的末尾包含实现文件MyTemplate.cpp 文件:
template <typename T>
MyTemplate<T>::MyTemplate(T value) : value(value) {}
template <typename T>
T MyTemplate<T>::getValue() const {
return value;
}总结
- 为了确保模板的定义在编译时可见,将
.cpp文件包含在头文件末尾是一种常见的解决方法。- 这种方式避免了链接错误,并保证了模板的实例化不会出错。
- 也可以将实现代码直接写在
.h文件中,但将.cpp文件分开并在头文件包含,能保持代码的整洁和结构的清晰。
typename可以替换为class。对于一个
const Vector<int>&,如果我们要使用对他进行访问,我们不能修改它。如果要进行访问,需要/只能使用
const成员函数(returnType function_name() const),这样就保证不会出错,否则编译器会报错。如果不声明为const,编译器无法确认这个方法会不会对其进行修改。在const成员函数内,我们无法对数据成员进行修改。函数也可以根据
const进行重载。T& at(size_t index) const;
这个函数有两个问题:
我们可以在外面进行修改,,如:
v.at(0) = 20;
我们的本意是不能进行修改,但是在函数外部发生了修改。
修改方法:
const T& at(size_t index) const;
以上例子的前提都是在传入的
v是const Vector<int>& v的情况下。但是如果传入的
Vector<int> &v,那么我们会发现:v.at(0) = 42; //error, can't assign to cosnt int&
解决方法:
可以定义两个版本的函数,实现函数的重载。
一个是:
const T& at(size_t index) const,另外一个是T& at(size_t index)。
介绍两个函数:
T& findElement(const T& value);
const T& findElement(const T& value) const;这两个函数在实现上高度相似,都是:
T& Vector<T>::findElement(const T& value)
{
//code
}如果直接写很浪费,可以采用下面的方法:
template<typename T>
const T& Vector<T>::findElement(const T& value) const
{
return const_cast<Vector<T>&>(*this).findElement(value)
}在
const_cast<Vector<T>&>(*this).findElement(value)中,主要做了三件事情:const_cast<Vector<T>&>(*this):移除this指针的常量性,使其可以调用非常量(非const)方法。- 调用
findElement(value):调用一个非const成员函数findElement,用于查找指定的value。 - 解释整体代码:通过
const_cast来调用一个原本在const对象上无法调用的非const方法。
分解解释
const_cast<Vector<T>&>(*this):const_cast是一个 C++ 运算符,用于移除指针或引用的const限定,允许我们在const对象上调用非常量方法。*this是一个指向当前对象的const指针(因为是在const成员函数中),类型是const Vector<T>&。const_cast<Vector<T>&>(*this)的意思是将*this从const Vector<T>&转换成Vector<T>&,从而移除const限定。- 这里的
Vector<T>&就是我们想要的类型。
调用
findElement(value):- 通过
const_cast转换后,可以在原本为const的对象上调用findElement(value)这个非const方法。 findElement(value)方法用于在Vector<T>对象中查找元素value。
- 通过
整体代码作用:
- 这一行代码的目的通常是因为查找逻辑被封装在
findElement中,但它并未被定义为const,而在const成员函数中无法直接调用该方法,所以通过const_cast进行转换。 - 注意:使用
const_cast破坏了对象的const限定,可能引发不安全的操作,因此在 C++ 中不推荐滥用const_cast。
- 这一行代码的目的通常是因为查找逻辑被封装在
除了
const_cast之外,还有mutable关键字,可以对const对象中声明为mutable的数据成员进行修改。
Template Functions
函数模板调用:
template<typename T> |
实例化:
//显式实例化 |
显式实例化和隐式实例化。
一般更推荐显式实例化:因为可以指明类型,避免不必要的问题,另外还可以避免指针的比较。
min<const char*>("jjj", "kkk"); |
隐式实例化还有缺点:就是不能完全匹配参数:
min(106, 3.14); //106是int, 3.14是double |
解决方法:
template<typename T, typename U> |
这里还有个前提:T必须是支持<操作的,也就是可以比较的。
不然编译器会在实例化这个函数后报错。
e.g
template <typename It, typename T> |
这里的It必须是迭代器类型。
在 C++ 中,函数模板可以通过 显式实例化 和 隐式实例化 来生成具体的函数。下面是这两种实例化的概念和用途:
1. 隐式实例化(Implicit Instantiation)
隐式实例化是指编译器根据模板的使用情况自动生成特定类型的函数实例。在代码中调用模板函数时,如果编译器发现没有该特定类型的实例,就会根据模板定义生成该实例。
示例:
T add(T a, T b) {
return a + b;
}
int main() {
int result = add(3, 4); // 编译器生成 int add(int, int)
double result2 = add(3.5, 2.5); // 编译器生成 double add(double, double)
return 0;
}在这个例子中,
add(3, 4)会触发add<int>(int, int)的实例化,而add(3.5, 2.5)会触发add<double>(double, double)的实例化。编译器自动生成所需的模板实例,这就是隐式实例化。2. 显式实例化(Explicit Instantiation)
显式实例化是指程序员在代码中显式地指定某个特定类型的模板实例。这通常用于加速编译或减少模板代码的重复生成。在显式实例化时,编译器会根据显示的指示生成特定类型的模板实例,即使在代码中没有直接调用该类型的模板实例。
显式实例化语法通常写在模板定义的文件(
.cpp文件)中,以避免多次生成相同的实例。语法:
示例:
template <typename T>
T add(T a, T b) {
return a + b;
}
// add_template.cpp
// 显式实例化
template int add<int>(int, int); // 生成 int 类型实例
template double add<double>(double, double); // 生成 double 类型实例在这个例子中,即使没有在代码中调用
add<int>或add<double>,编译器仍然会生成int和double类型的add实例。显式实例化的作用
- 控制模板实例化:减少编译器自动生成的实例个数,从而缩小可执行文件大小。
- 提高编译速度:如果某个模板函数会在多个文件中用到不同的类型,显式实例化可以避免重复生成相同的模板实例。
- 代码分离:可以在头文件中定义模板函数,而在实现文件(
.cpp文件)中实例化所需类型,减少头文件中代码的膨胀。总结
- 隐式实例化:编译器根据使用情况自动生成模板实例。
- 显式实例化:程序员显式指定模板实例,通常用于减少模板生成、优化编译时间和控制可执行文件大小。
显式实例化适合在大型项目中使用,尤其是当模板实例数量较多、模板实例化较复杂时,有助于提高编译效率并控制代码生成。
上面介绍的函数模板可以发现一个问题:我们需要确定模板的约束?如何确定?如何提前知晓?
比方说:有些需要支持<,有些需要支持某种类型如iterator。
下面引入了concept。使用concept可以提高代码的可读性,提供更加友好的编译器报错信息。
template <typename T> |
这个代码定义了一个 C++20 的 概念(Concept)
Comparable,用于约束类型T,要求T类型的两个const实例(a和b)之间能够通过某种表达式返回一个可以转换为bool的结果。下面是对该代码的逐行解释:
concept Comparable = requires(const T a, const T b) {
{a < b} -> std::convertible_to<bool>;
};逐行解释
template <typename T>:定义一个模板参数T,用于指定类型。
concept Comparable:定义一个名为Comparable的概念,它是一个模板约束,专门用于指定T需要满足的条件。
requires子句:
requires子句定义了一个表达式,描述了该概念约束的具体要求。requires(const T a, const T b)表示这个概念要求两个const T类型的变量a和b能够进行指定的操作。
{ a < b } -> std::convertible_to<bool>;:
- 这是一个约束表达式,表示
{ a < b }表达式的结果必须能转换为bool类型。任何在其中编译的内容必须没有错误。- 其中,
std::convertible_to<bool>是一个标准库提供的概念,用于检查某种类型是否可以隐式转换为bool类型。- 注意,这里
{a < b}看起来像是一个逗号表达式,实际是在测试a和b的比较结果是否能转换成布尔值。实际用途
这个概念用于确保某个类型
T的对象可以用在需要布尔结果的比较操作中,比如可以被用于==,<,<=,>,>=等运算符。比如,如果一个函数要求它的参数类型满足Comparable概念,则可以保证这些参数在比较操作中会返回一个布尔值。使用示例
假设我们有一个函数
isEqual,要求传入的参数类型满足Comparable概念:
template <typename T>
concept Comparable = requires(const T a, const T b) {
{ a == b } -> std::convertible_to<bool>;
};
template <Comparable T>
bool isEqual(const T& x, const T& y) {
return x == y;
}
int main() {
int a = 5, b = 10;
std::cout << isEqual(a, b) << std::endl; // 输出 0 (false)
std::string s1 = "hello", s2 = "world";
std::cout << isEqual(s1, s2) << std::endl; // 输出 0 (false)
}在这个示例中,
isEqual函数要求其参数类型满足Comparable概念,因此只有那些支持==并返回bool的类型才能作为参数传入。
C++20 中的 concept(概念)是一种用于模板编程的新特性,用来定义模板参数的约束条件。概念帮助开发者明确表达某些类型在模板中的适用性,从而增强代码的可读性、可维护性,并在编译阶段提供更好的错误信息。
1. Concept 的作用
在模板编程中,类型和操作可能并不总是符合预期。例如,模板可能要求一个类型可以被比较、加法或迭代,但如果用户传入不满足要求的类型,编译器报错会比较难懂。Concept 通过显式地描述模板参数需要满足的条件来解决这个问题。如果类型不满足某个概念要求,编译器会清晰地指出不符合的地方。
2. 定义 Concept 的语法
Concept 是一种布尔表达式,可以使用
requires子句或者bool常量表达式来定义:
concept ConceptName = /* 布尔表达式或 requires 子句 */;3. 示例:定义一个基本 Concept
假设我们需要一个
Addable概念,要求类型T支持加法操作。可以使用以下代码:
template <typename T>
concept Addable = requires(T a, T b) {
{ a + b } -> std::convertible_to<T>; // a + b 的结果应能转换为类型 T
};在这里,
Addable概念规定T类型的两个实例之间能够进行加法运算,并且返回的结果类型可以转换为T。4. 使用 Concept 限制模板参数
定义了一个概念后,可以将其用作模板参数的约束条件:
T add(T a, T b) {
return a + b;
}上面这个
add函数模板使用了Addable概念,确保T类型支持加法运算。如果传入一个不支持加法的类型,编译器会给出清晰的错误信息。5. Concept 的
requires子句
requires子句是 Concept 的核心部分,用于定义类型的特定要求。比如,可以要求一个类型T必须有==运算符,并且返回布尔值:
concept EqualityComparable = requires(T a, T b) {
{ a == b } -> std::convertible_to<bool>;
};6. 使用 Concept 的方式
有三种主要方式可以在模板中使用 Concept:
模板参数列表中直接使用:
T add(T a, T b) { return a + b; }
requires关键字:
requires Addable<T>
T add(T a, T b) { return a + b; }尾置
requires子句:
T add(T a, T b) requires Addable<T> {
return a + b;
}7. Concept 的实际意义和优势
- 提高代码可读性:可以清楚地定义模板参数的预期能力,避免复杂的
std::enable_if和 SFINAE 技术。- 编译器友好:在模板使用不当时提供更清晰、直观的错误信息。
- 编译期检查:在编译阶段进行类型检查,提升模板代码的安全性和效率。
8. 常见标准库概念
C++20 标准库引入了许多内置概念,方便约束模板参数,例如:
std::integral:整数类型。std::floating_point:浮点数类型。std::same_as<T, U>:类型相同。std::convertible_to<T>:类型可转换。总结
Concept 是一种强大且直观的方式,用于简化 C++ 模板编程中的约束管理。它不仅提升了模板代码的表达力,还改进了模板编程中的错误提示,让编写和维护模板代码变得更加轻松。
variadic templates:
Variadic Template(可变参数模板)是 C++ 中的一种模板特性,允许定义的模板可以接受可变数量的模板参数。它最早在 C++11 中引入,使编写灵活的模板函数和类变得更加简单和高效。
1. 基本语法
Variadic Template 的参数定义方式是在模板参数名称后加上省略号
...。这可以让模板接受任意数量的类型参数。具体语法如下:
void functionName(Args... args) {
// 代码实现
}
typename... Args:定义一个可变数量的模板参数Args,可以是 0 个或多个。Args... args:展开参数包,将所有传入参数按顺序展开。2. Variadic Template 的应用
2.1 Variadic Template 函数
可以使用 Variadic Template 定义接受任意数量参数的函数,例如:
template <typename... Args>
void print(Args... args) {
(std::cout << ... << args) << '\n'; // 参数展开
}
int main() {
print(1, 2, 3, "hello"); // 输出:123hello
print("Variadic", " ", "Templates", " ", 2024); // 输出:Variadic Templates 2024
return 0;
}在这个例子中,
(std::cout << ... << args)将所有参数传递给std::cout逐个打印。2.2 Variadic Template 类
Variadic Template 也可以用来定义类模板,允许一个类接受多种类型参数:
template <typename... Args>
class MyContainer {
std::tuple<Args...> data; // 使用 std::tuple 存储参数
public:
MyContainer(Args... args) : data(args...) {} // 构造函数接受多个参数
void print() {
std::apply([](auto&&... args) { ((std::cout << args << " "), ...); }, data);
std::cout << '\n';
}
};
int main() {
MyContainer<int, double, std::string> container(1, 3.14, "Hello");
container.print(); // 输出:1 3.14 Hello
return 0;
}在这个例子中,
MyContainer类可以接受任意数量的模板参数,并将它们存储在std::tuple中。3. 参数包展开(Parameter Pack Expansion)
在使用 Variadic Template 时,参数包(parameter pack)需要展开,以便对每个参数执行相同的操作。展开参数包的常见方式有两种:
- 递归展开:利用递归函数模板逐个处理每个参数。
- 折叠表达式(C++17 引入):通过
(... op args)或(args op ...)语法将所有参数一起展开。3.1 折叠表达式示例
折叠表达式是一种简化的参数展开方式,例如:
void printAll(Args... args) {
(std::cout << ... << args) << '\n'; // 左折叠:输出所有参数
}折叠表达式可以让代码更简洁、易读。
4. Variadic Template 的应用场景
Variadic Template 在处理任意数量的参数时非常有用,常见的应用场景包括:
- 日志函数:接收任意数量的参数并输出日志信息。
- 智能容器:设计可以容纳任意类型和数量参数的容器类。
- 泛型工厂函数:创建任意类型和数量参数的对象。
总结
Variadic Template 是 C++ 的强大功能,允许模板支持任意数量的参数。它在简化模板编程、增强代码灵活性方面起到了重要作用,尤其适用于函数参数数量不定的场景。通过折叠表达式等语法,Variadic Template 的代码可以写得更简洁清晰,编写变得更加高效。
引入一个例子
min(2.4, 7.5); |
如果直接重载很麻烦,我们可以使用可变参数模板:
这里先引入一个方法:
template <Comparable T> |
template <typename T> |
这个方法采用递归,获取最小值,但是这个方法不太高效,因为每一次递归时都需要进行复制vector。
和我们的理想效果有一些出入,这里最终引入可变参数模板:
//最基本的情况,用于停止递归调用 |

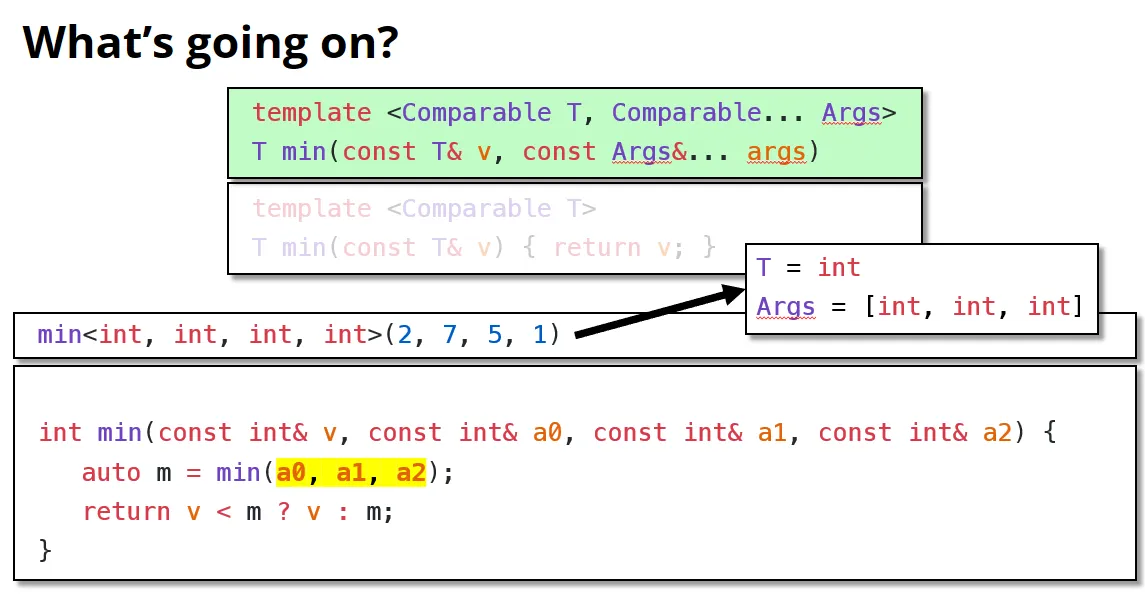

再列举可变参数模板的一个例子:可变参数的类型不需要是一样的(上面提到的可以发现都是一样的数据类型)

上面的这个问题是vector只可以接收一种数据类型。解决方法如下:


模板元编程是在编译时期执行函数代码的技术,可以提高运行效率。如下图:可以发现计算结果在编译时已经计算完毕了。

模板元编程(Template Metaprogramming, TMP)是一种利用 C++模板系统在编译时进行计算和代码生成的编程技术。它允许在编译阶段执行一些逻辑操作,进而自动生成代码,减少运行时的计算负担。这种方法主要用于创建高效、通用的库,比如
std::tuple和std::variant等标准库组件。基本原理
模板元编程的核心思想是在编译时执行代码,通过递归的模板实例化来进行计算。C++模板系统支持类型和常量作为模板参数,因此可以在模板中实现类似于循环、条件判断和递归等控制结构。
模板元编程的主要特性
静态多态性:模板元编程允许在编译时选择不同的代码路径,实现静态多态。这避免了运行时开销,提高了性能。
编译时计算:通过递归模板实现一些计算逻辑,例如计算阶乘、斐波那契数列、判断类型是否相同等。
类型特征和类型转换:模板元编程广泛应用于类型特征的推导,例如
std::is_integral、std::is_pointer等类型特征类。C++标准库中type_traits就是一个主要依赖模板元编程的库,用于在编译时分析和操作类型。简单示例:编译时计算阶乘
以下是一个简单的模板元编程示例,用来计算阶乘:
struct Factorial {
static const int value = N * Factorial<N - 1>::value; // 递归计算
//or
enum {value = N * Factorial<N - 1>::value};
};
// 特化,当 N=0 时结束递归
template <>
struct Factorial<0> {
static const int value = 1;
//or
enum {value = 1};
};
int main() {
int result = Factorial<5>::value; // 编译时计算 5 的阶乘
std::cout << "Factorial of 5: " << result << std::endl; // 输出: 120
return 0;
}在上面的代码中,
Factorial是一个模板结构体,递归地计算阶乘。当N为 0 时,终止递归。这种计算在编译时完成,因此不会影响运行时性能。应用场景
类型推导和类型转换:例如
std::enable_if、std::conditional、std::is_same等模板。通用容器和数据结构:如
std::tuple,利用模板元编程实现可以存储任意类型的元素。静态检查和编译时断言:在编译阶段检查某些条件是否满足,避免运行时错误。
数学计算:如编译时计算斐波那契数列、阶乘等。
模板元编程的优缺点
优点:
- 可以提高程序性能,将一部分工作从运行时移到编译时。
- 代码更通用,可以处理不同类型的输入。
缺点:
- 模板元编程的语法复杂,调试和错误定位难度较高。
- 编译时间会增加,特别是在递归深度较高的情况下。
总结
模板元编程是 C++ 中一项强大但复杂的技术,用于编译时的类型和常量计算。它在性能优化和通用编程中有着广泛的应用,但也带来了一定的复杂度。
另外的一个例子:
template <> |
模板元编程(Template Metaprogramming,TMP)在实际应用中的一些用法:
在编译时将结果嵌入可执行文件中:例如在编译期间计算阶乘值。通过编译时计算,把一些结果直接嵌入到最终的可执行文件中,以减少运行时的计算需求,从而提高效率。
优化矩阵、树或其他数学结构:通过 TMP,可以在编译时优化或简化某些数学数据结构的实现,比如在编译时计算矩阵的属性、进行树的构建等。这可以避免运行时的复杂计算,使代码更高效。
基于策略的设计:通过模板传递行为参数。所谓“策略设计”是一种编程模式,在 TMP 中可以通过模板参数来指定不同的策略或行为。例如可以将某种算法的具体实现(如排序算法)作为模板参数传递,动态生成不同版本的代码。
Boost MPL 库:Boost MPL(MetaProgramming Library)是 C++ Boost 库的一部分,专门用来支持模板元编程。这个库提供了大量用于编译时计算和类型操作的模板工具,使得 TMP 的应用更加简便和强大。
总结
模板元编程在实际中主要用于提高程序性能,减少运行时计算负担,并实现灵活的代码设计。它不仅适用于数学计算和结构优化,还能增强代码的通用性和可维护性。
后续了解一下 boost,这个不太懂?

TMP虽然在编译阶段就执行代码,但是其编写的代码可读性不高。
如何在任何时候都可以在编译时期执行代码呢?并且提高可读性?
这里引入constexptr和consteval关键字:

Functions And Lambdas
predicate:表示返回值为bool的函数
将函数作为一个参数传递到另外一个函数中。
//原来的版本 |
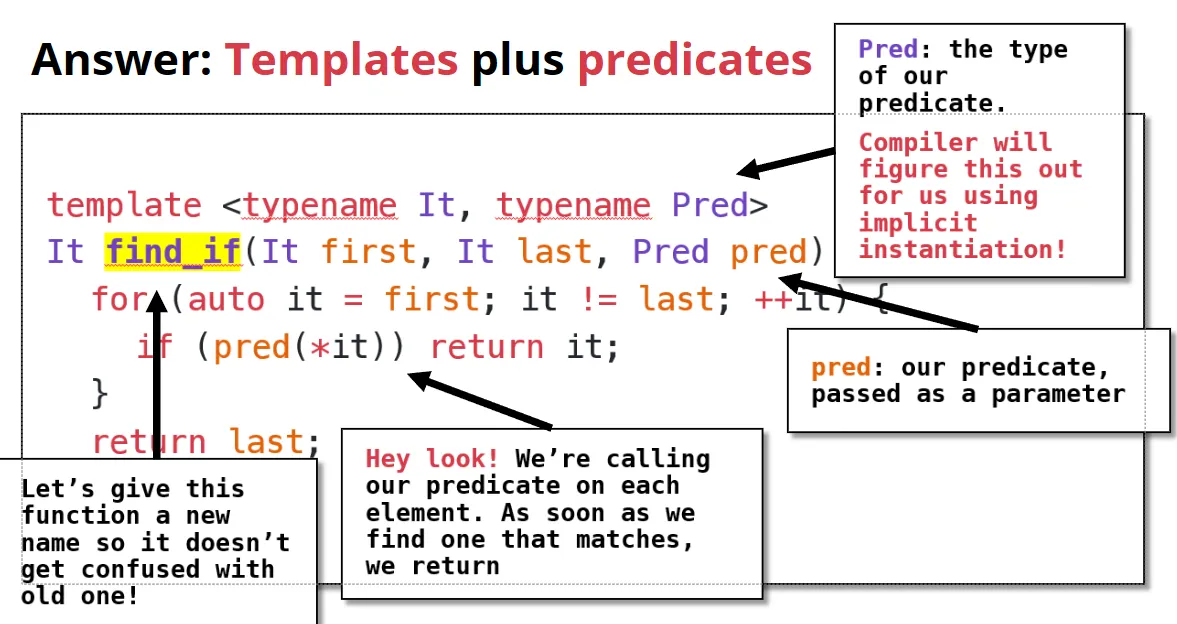
这里的Pred是一个函数指针。
find_if(v.begin(), v.end(), isVowel); |
由此继续引入:如果我们想要实现一个lessThanN,这个是我们指定的,将这个函数应用于find_if函数,怎么办?
lessThanN函数的实现不难,但是上面find_if的代码中,我们只传入了一个参数,所以我们怎么办?
可以再添加一个参数,但是有没有其他的方法?
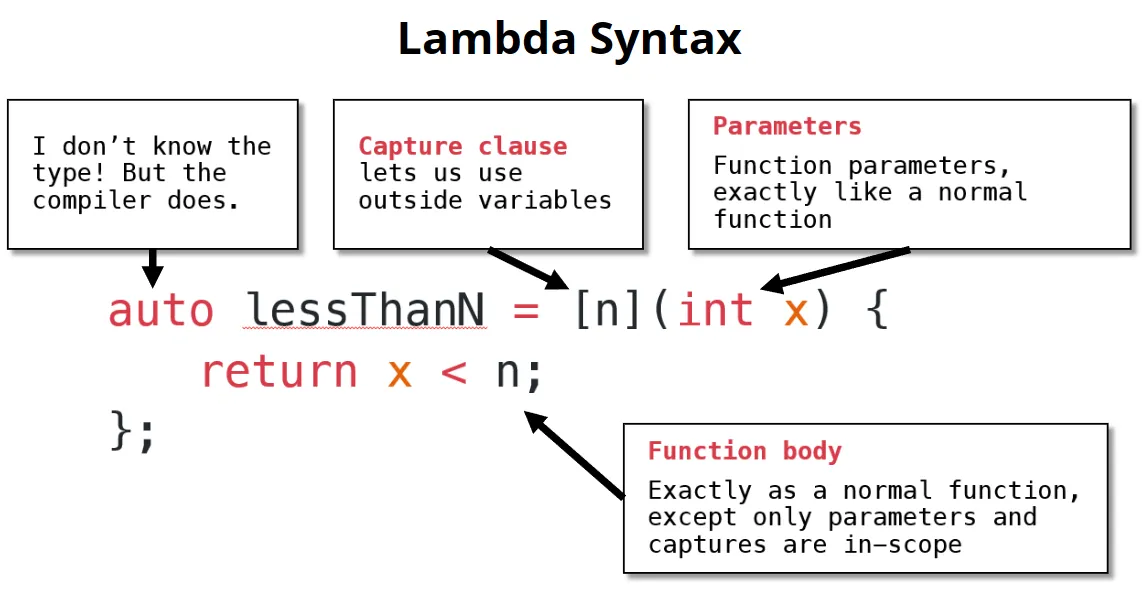
这里引入lambda表达式,解决这个问题。

functor
在编程中,Functor(函子)概念源于数学的范畴论,并在函数式编程和面向对象编程中被广泛应用。根据上下文,Functor 可以指不同的东西:
1. 在函数式编程中的 Functor
在函数式编程中,Functor 是一个支持
map操作的结构,允许你对结构内部的值进行操作,而不改变结构本身。例如在 Haskell 中,List和Maybe类型就是常见的 Functor。一个 Functor 满足以下两个要求:
- 封装值:Functor 包装了某种数据。
- 映射功能:可以通过一个函数对封装的值进行操作,并生成新的 Functor。
假设我们有一个 Functor
F<T>,通过map操作,我们可以将一个函数f应用于其中的值。即使结构内部的数据类型改变,结构本身不发生改变,类似于下面的伪代码:
map :: Functor f => (a -> b) -> f a -> f b2. 在 C++ 中的 Functor
在 C++ 中,Functor 通常指 重载了
operator()的对象,使其能够像函数一样被调用。这样的对象称为函数对象,用于提供灵活的函数调用方式。例如:
class Add {
public:
int operator()(int a, int b) {
return a + b;
}
};
int main() {
Add add;
std::cout << add(3, 4) << std::endl; // 输出:7
return 0;
}在这个例子中,
Add类重载了()运算符,使得Add类的对象可以像普通函数一样调用。这在需要将逻辑封装在对象中时非常有用,例如传递到 STL 的算法中(如std::sort)。总结
- 函数式编程中的 Functor:一种可以映射操作的结构,如
List或Maybe,可以对封装的值应用函数。- C++ 中的 Functor:重载了
operator()的对象,使其像函数一样调用,常用于灵活的函数调用。
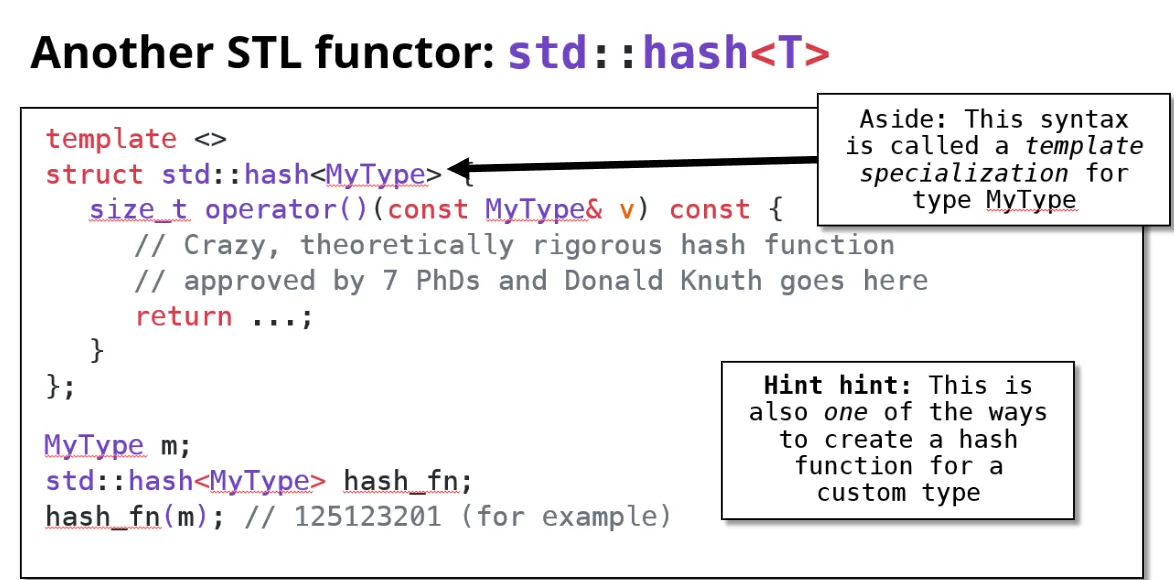
后续了解一下模板特化是什么?
lambda的底层原理:
当我们使用lambda时,会产生对应的functor(有点震撼。。。)
这里的auto实际上是std::function:一种重要的服务于函数/lambdas的数据类型,任何的functor``lambda``function指针都可以转换为它,一般可以使用auto关键字进行替代。
std::function<bool(char)> vowel = isVowel; |


后面是介绍<algorithm>中的一些算法,直接自己看官方文档就行。
本来是介绍了实现一个新的算法(看不太懂),由此再引入ranges,直接看ranges就行。
ranges:任何具有begin和end的一切事务事物。
std::vector<char> v = {'1', '2', '3', '4', '5'}; |
其实我们关心的是整个容器,可以替换为:
auto it = std::ranges::find(v, 'c'); |

有些不太理解?
views:还是ranges但是懒操作。
在 C++20 中,views 是标准库提供的一个新概念,它属于 Ranges 库的一部分,旨在简化对集合或序列的操作。通过使用 views,可以创建延迟计算的视图,对数据进行过滤、转换和组合,而不改变原始数据。
views 的特点
- 延迟计算:views 是惰性求值的,这意味着不会立即执行任何操作,只有在需要访问元素时才会进行计算,类似于 Python 的生成器。
- 不改变原始数据:views 是对原始数据的非拥有性视图,不会修改底层容器。
- 高效性:由于 views 不会复制数据,而是直接作用于原始数据,因此性能较高。
常见的 views 操作
C++20 的 views 提供了多种操作,可以用于过滤、变换等。例如:
std::views::filter:筛选符合条件的元素。std::views::transform:对每个元素应用某种变换。std::views::take和std::views::drop:获取前n个或跳过前n个元素。std::views::reverse:反转序列中的元素顺序。views 的使用示例
以下是一个简单的示例,展示了如何使用
std::views::filter和std::views::transform:
int main() {
std::vector<int> numbers = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
// 使用 views 筛选偶数,并将结果加倍
auto even_doubled = numbers
| std::views::filter([](int n) { return n % 2 == 0; })
| std::views::transform([](int n) { return n * 2; });
// 输出结果
for (int n : even_doubled) {
std::cout << n << " "; // 输出: 4 8 12 16 20
}
return 0;
}views 的优点
- 代码简洁:可以链式调用多个操作,逻辑清晰简洁。
- 性能更优:避免了多次拷贝和重新分配,使用惰性求值提高了性能。
- 减少内存开销:不产生额外的数据拷贝,仅创建对原数据的视图。
总结
C++20 的 views 提供了灵活、简洁且高效的数据操作方式,使得在容器上进行常见的数据操作(如过滤、变换)更加方便。
下面看 PPT
例子比较好懂:关键是支持filter和transform操作。



ranges和view使用建议:
- 更少关注迭代器
- 约束算法,报错信息更加友好
- 代码的可读性更高
- 缺点是太新了,不是所有的特性都非常完善
- 可能缺少编译器支持
Operator Overloading
运算符重载的要求:有一定的顺序关系,并且是可以比较的,逻辑上可以确定的。
不可重载运算符:
:: ?: . .* sizeof() typeid() cast()。
运算符重载有两种:作为成员函数进行重载,作为非成员函数进行重载。
推荐使用非成员函数实现:
优点:
- 左侧比较的对象可以不一定是类类型。
- 可以重载我们没有的类类型。
但是实现以上方法,需要访问类的数据成员(一般是private),所以我们采取如下方法:使用友元friend。从而可以访问私有数据成员。
复习一下各类运算符重载的方法。