
Ch8 Part2
Ch8 part2
Memory Hierarchy
为什么要有存储层次结构?
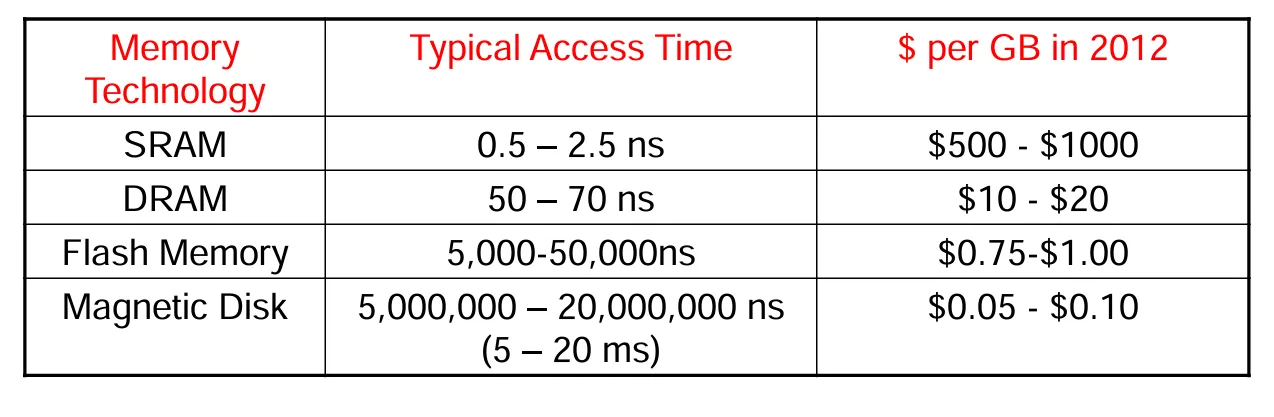
理想存储的特点:理想的存储应该具有零访问时间(即没有延迟)、无限的存储容量和零成本这三个特点。
理想存储面临的问题:然而,这些要求之间是相互矛盾的。一般来说,存储容量越大,速度往往越慢,因为容量增大意味着需要更长的时间来确定存储位置;而且速度越快的存储设备通常价格也越昂贵,例如静态随机存取存储器(SRAM)和动态随机存取存储器(DRAM)在技术和成本上就体现了这种差异。
总结问题:我们期望存储设备能够同时具备速度快、容量大、价格便宜的特点,但仅靠单一层次的存储是无法实现这些要求的。
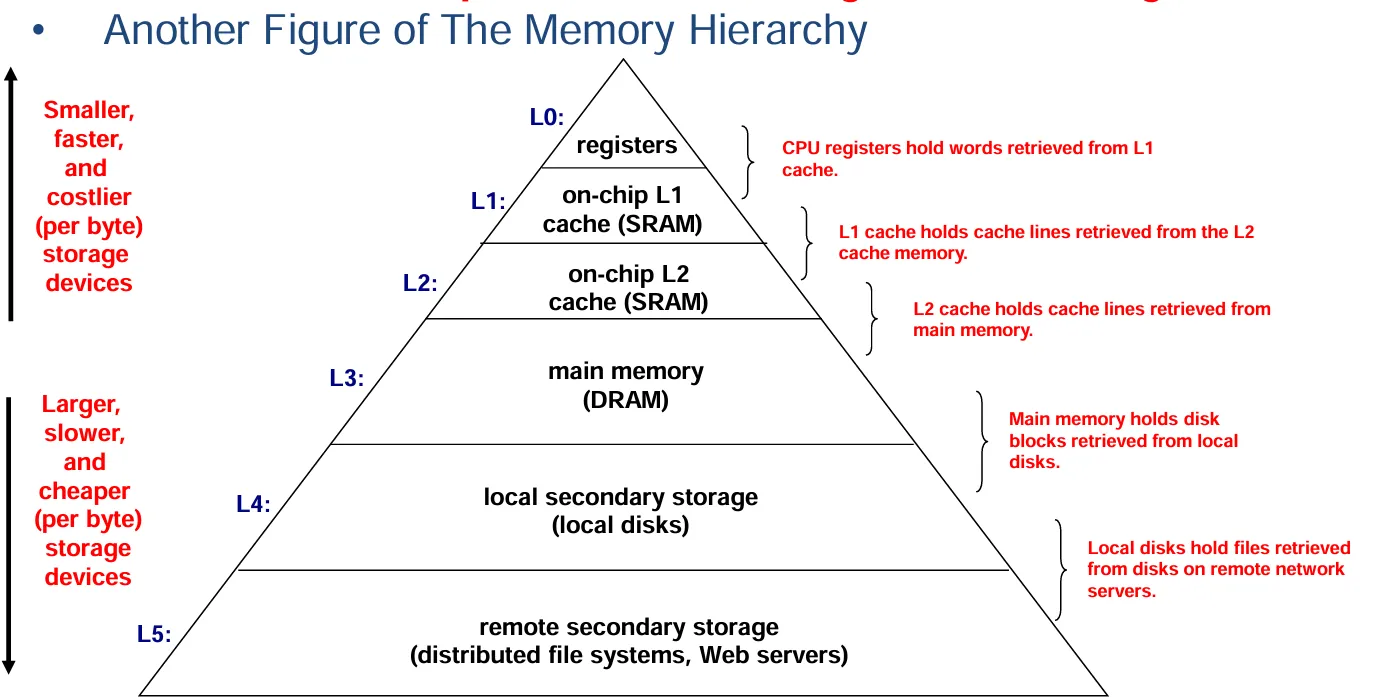
解决思路:为了营造出一种“速度快且容量大”的主存储器的假象,我们采用多级存储的方式。这些存储级别离处理器越远,存储容量越大,但速度越慢。并且要确保处理器所需的大部分数据都存储在速度较快的存储级别中。
缓冲区(Buffer)的概念
- 定义:缓冲区是一种相对较小但速度更快的存储设备,它充当着较大且速度较慢设备中部分数据的暂存区域。
- 层级关系体现:对于每一个层级 k 而言,处于该层级的速度更快、尺寸更小的设备会作为层级 k + 1 中更大、更慢设备的缓冲区。所有的数据最终都是存储在最低层级上,并且数据会在相邻的两个层级之间进行复制。
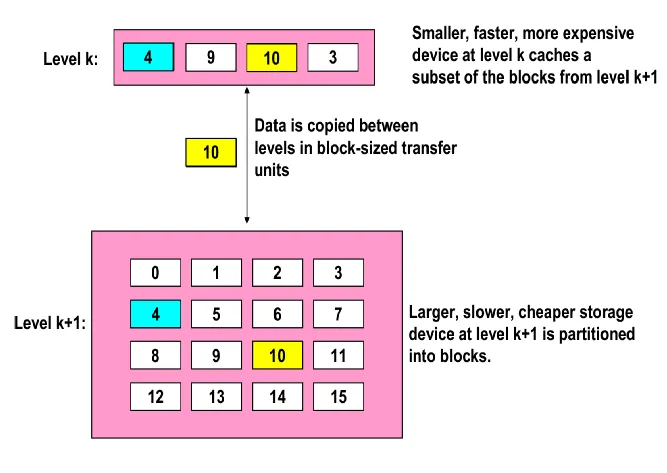
通用缓冲概念
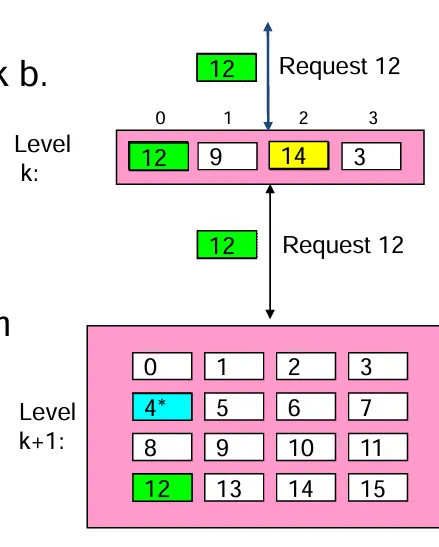
- 命中(Hit)情况:当程序需要某个对象 d(该对象存储在某个数据块 b 中)时,如果程序能在层级 k 的缓冲区中找到数据块 b(例如找到块 14),这种情况就被称作“命中”。
- 未命中(Miss)情况:要是数据块 b 不在层级 k 的缓冲区中,那么层级 k 的缓冲区就必须从层级 k + 1 去获取该数据块(例如需要获取块 12 这种情况),这就是“未命中”的情况。
存储层次结构的工作原理——利用局部性原理
- 程序与局部性的关系:编写良好的程序往往会呈现出较好的局部性特点,也就是说在任意时刻,程序通常只会访问地址空间中相对较小的一部分区域。
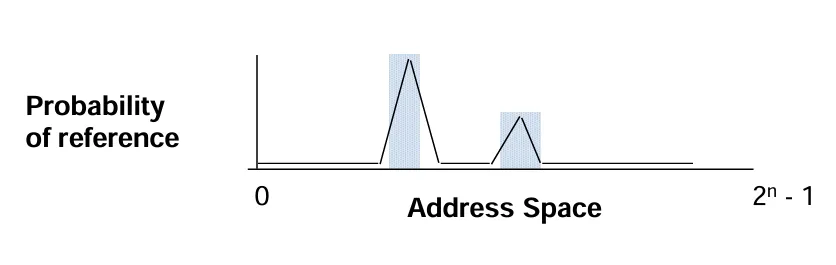
局部性原理的具体内容
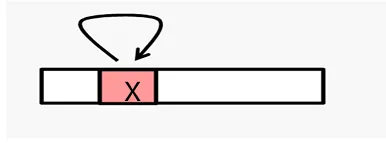
- 时间局部性(Temporal Locality):体现的是时间上的局部性,如果某个数据项在近期被引用过,那么它很有可能在不久之后会再次被引用。
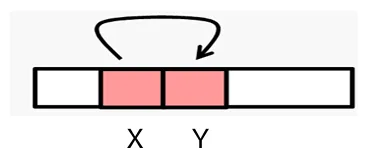
- 空间局部性(Spatial Locality):反映的是空间上的局部性,当一个数据项被引用时,与其相邻的数据项很可能也会很快被引用。
局部性原理在存储层次结构中的体现
- 时间局部性方面:基于时间局部性,要将最近被访问的数据项放置在更靠近处理器的位置,这样便于处理器能更快速地再次访问它们。
- 空间局部性方面:根据空间局部性,会把由连续字组成的数据块移到存储层次结构中较高的层级,以提高访问效率。
存储层次结构工作原理总结
访问频率差异:程序访问层级 k 的数据往往要比访问层级 k + 1 的数据更为频繁。
层级特性差异:正因为如此,层级 k + 1 的存储设备可以速度更慢些,相应地其每比特的成本也会更低,而且容量可以更大。
最终效果呈现:通过这样的存储层次结构,最终能形成一个大容量的存储池,其成本和位于底层的廉价存储相当,但向程序提供数据的速率却能达到靠近顶层的快速存储的水平,从而在成本和性能上实现较好的平衡。
存储层次结构设计者面临的四个问题
- 问题 1:块在高层级中可以放置在哪里?(块放置)
- 这涉及到在存储层次结构的高层级中,如何确定一个数据块的存储位置。例如,是可以随意放置在空闲位置,还是有特定的规则,如按照某种顺序或者映射关系来放置数据块。
- 问题 2:如果块在高层级中,如何找到它?(块识别)
- 当需要访问一个数据块,并且已知它可能存储在高层级中时,就需要一种有效的方法来识别它的具体位置。这可能涉及到使用索引、标签或者其他标识机制来快速定位数据块。
- 问题
3:在未命中(miss)的情况下,应该替换哪个块?(块替换)
- 当在高层级中没有找到所需的数据块(未命中),需要从下一层级获取数据块放入高层级时,就需要决定替换高层级中的哪个现有数据块。这可能需要考虑数据块的使用频率、最近使用时间等因素来选择合适的替换策略。
- 问题 4:写入操作时会发生什么?(写入策略)
- 当需要对存储在层次结构中的数据进行写入操作时,需要确定具体的写入方式。例如,是只写入高层级,还是同时更新高层级和下一层级,或者有其他的写入规则来确保数据的一致性和存储效率。
这些问题将在下一节解决。
Cache Memories
存在的问题
处理器的性能提升速度远比动态随机存取存储器(DRAM)的速度提升速度要快得多,这就导致了两者之间在速度匹配上出现了差距。
高速缓存(Cache)的相关情况
- 基本特性:高速缓存是基于静态随机存取存储器(SRAM)构建的小型且速度很快的存储器,它由硬件自动进行管理。
- 所处位置与作用:它充当着CPU 和主存储器之间的缓冲区,主要功能是存放主存储器中那些被频繁访问的数据块。
高速缓存的目的
其目的在于让主存储器的访问速度能够接近当前可获取到的速度最快的存储器的速度,与此同时,还能以相对较为廉价的半导体存储器的成本,来提供大容量的存储功能,从而在一定程度上缓解处理器与主存储器之间因速度差异带来的性能影响。
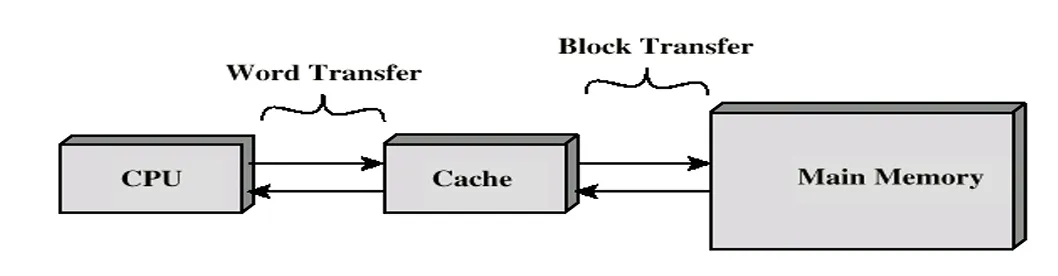
Cache and Main Memory Organization Figure
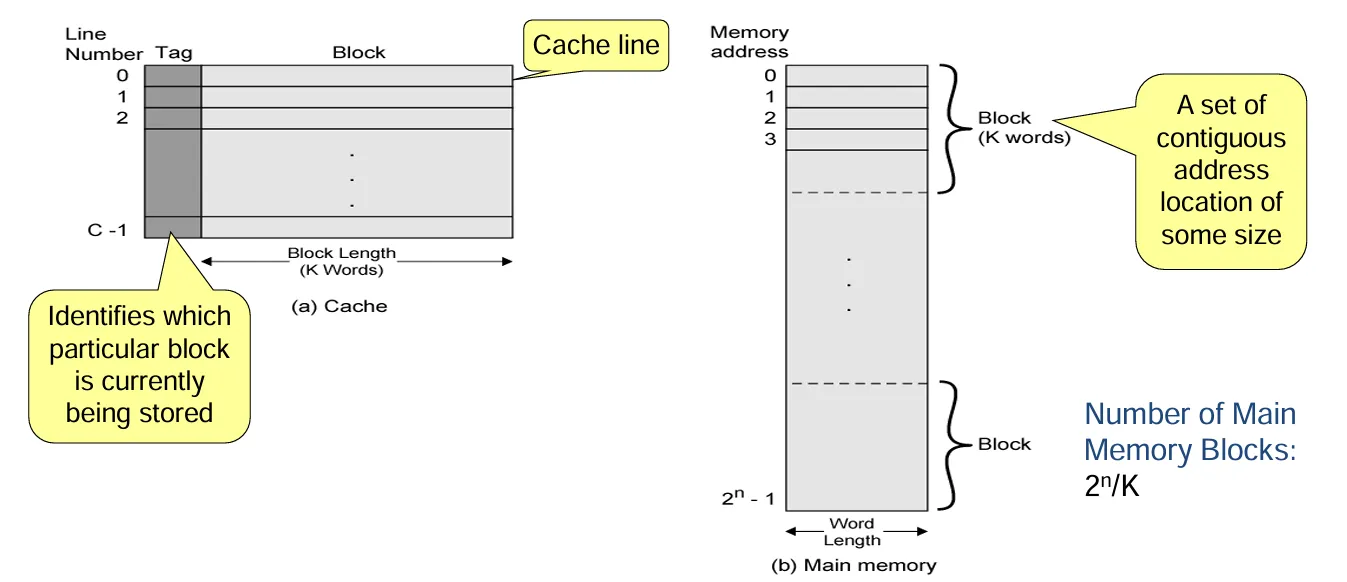
命中(Hit)与未命中(Miss)的概念
- 命中(Hit):当对高速缓存(Cache)进行访问时,能够在缓存存储器中找到所需的数据,这种情况就称为命中。
- 未命中(Miss):如果对高速缓存进行访问,却没能在其中找到所需的数据,那就不得不转而访问主存储器,这种情况就是未命中。
命中率(Hit Rate)相关
- 命中率定义:它指的是能够通过高速缓存满足的内存访问次数所占的百分比。对于高性能计算机而言,很高的命中率(远远超过 0.9)是至关重要的。
- 未命中率计算:未命中率等于 1 减去命中率(Miss Rate = 1 - (Hit Rate))。
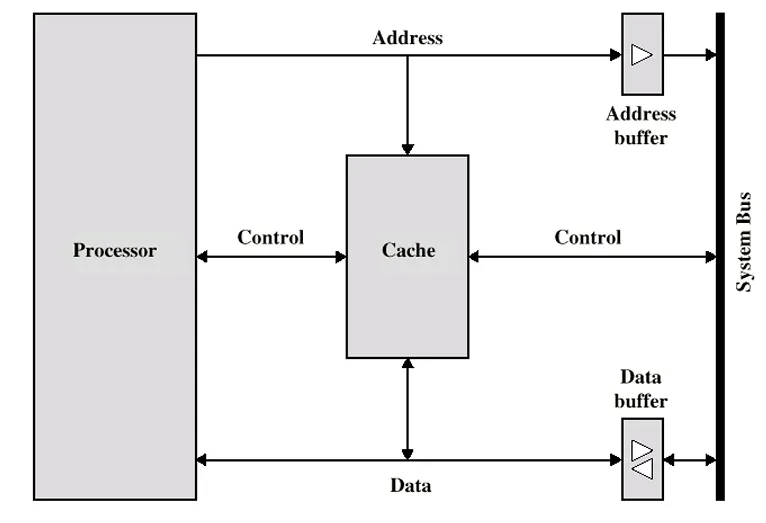
处理器与高速缓存的交互特点
处理器不需要明确知晓高速缓存的存在情况。它只是简单地使用指向内存中相应位置的地址来发出读(Read)和写(Write)请求。然后由高速缓存控制电路来判断所请求的字当前是否存在于高速缓存之中。
处理器读请求的不同情况
- 高速缓存读命中(Cache Read Hit):此时会直接将所请求的字转发给处理器。
- 高速缓存读未命中(Cache Read Miss)的两种处理方式:
- 常规方式:先从主存储器中将包含所请求字的整个数据块复制到高速缓存中,然后再将特定的所请求字转发给处理器。
- 加载穿透/提前重启(Load Through/Early Restart)方式:在将所请求的字转发给处理器的同时,从主存储器中将包含该请求字的整个数据块复制到高速缓存中。
- 高速缓存读未命中在当代缓存组织中的情况(Cache Read Miss - Contemporary Cache Organization):
高速缓存映射方案相关问题概述
- 块放置问题(Cache Mapping Schemes):在高速缓存中,一个数据块可以放置在哪里,这是由映射方案来确定的。
- 块识别问题(Block Identification):如果一个数据块已经在高速缓存中了,那么要通过怎样的方式去找到它,这也是需要考虑的方面。
- 替换算法问题(Replacement Algorithms):当发生高速缓存未命中的情况时,应该替换掉高速缓存中的哪个数据块,这就需要相应的替换算法来决定。
- 写入策略问题(Write Policy):在写入操作时,若遇到写入命中(write hit)情况会怎样处理,遇到写入未命中(write miss)情况又该如何应对,这些都属于写入策略需要涵盖的内容。
映射方案的基本作用(Mapping Scheme (1))
- 确定块放置位置:映射方案决定了数据块最初被复制到高速缓存时将会被放置的位置。
- 地址转换功能:同时,它还需要将生成的主存储器地址转换为高速缓存中的相应位置地址。因为当 CPU 为主存储器中某个特定字生成地址,且该数据恰好就在高速缓存中时,原来的主存储器地址是不能直接用来访问高速缓存的,需要进行相应的转换。
具体的映射方案及相关假设
- 三种映射方案:主要有直接映射(Direct Mapping)、关联映射(Associative Mapping)和组关联映射(Set Associative Mapping)这三种方案。
- 相关假设说明:
- 假设存在高速缓存行(Cache line)用\(L_i\)表示,内存块(Memory block)用\(B_j\)表示,其中\(i = 0, 1, \ldots, m - 1\),\(j = 0, 1, \ldots, n - 1\),这里\(m = 2^r\),\(n = 2^s\)。
- 每个缓存行或者内存块都由\(k = 2^w\)个连续的字组成。
- 主存储器地址是由\(s + w\)位来表示的。 (\(s\)确定是哪一块内存块,\(w\)确定是哪一个字)。
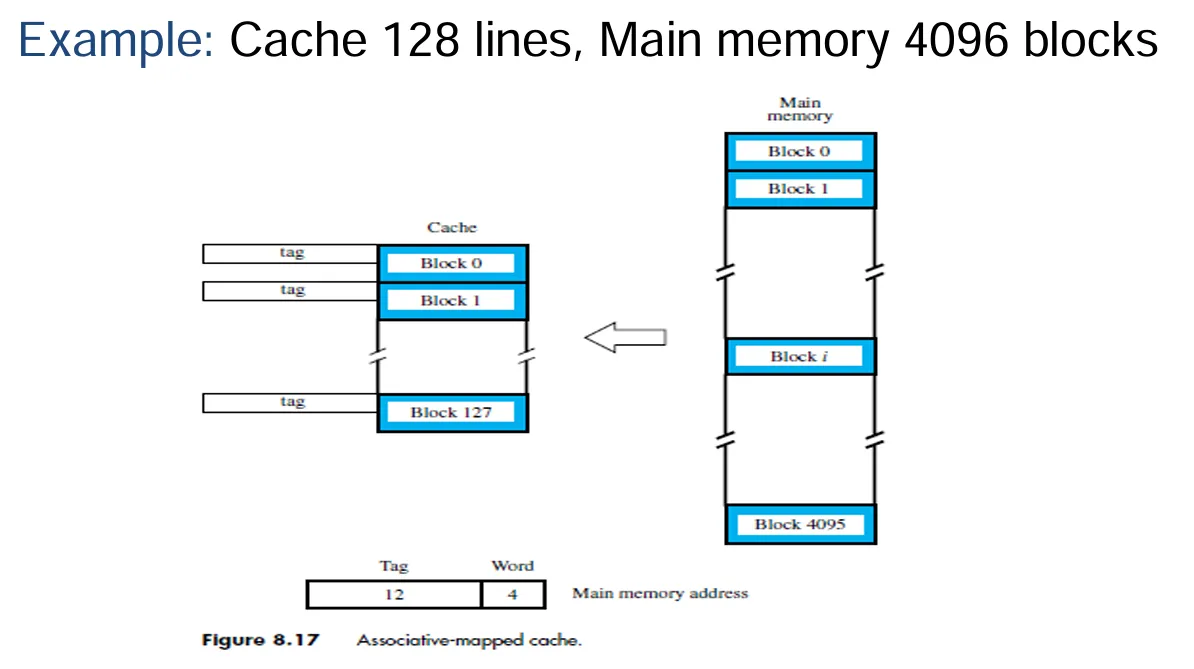
直接映射法
主存块与缓存行的映射关系
- 在直接映射方式下,主存储器的每一个数据块都只会映射到唯一的一个高速缓存行上。也就是说,如果某个主存块存在于高速缓存当中,那它必然处于某一个特定的位置上。
映射函数说明
- 其映射函数为\(i = j \bmod m\)。在这个函数里,\(i\)代表的是高速缓存行的编号,\(j\)表示的是主存储器数据块的编号,而\(m\)则是高速缓存中所包含的缓存行的数量。通过这样的计算方式,就能确定主存块具体映射到哪个高速缓存行上。
直接映射(Direct Mapping)的缓存行表与主存地址结构
- 缓存行表:在直接映射方式下,有相应的缓存行表用于记录相关信息。
- 主存地址结构:主存地址由不同部分构成,其中最低有效 w 位用于标识唯一的字,而最高有效 s 位用来指定一个内存块。并且,最高有效 s 位又会被拆分成一个缓存行字段 r 位以及一个标记(tag)字段(共 s - r 位,且是最高有效部分)。

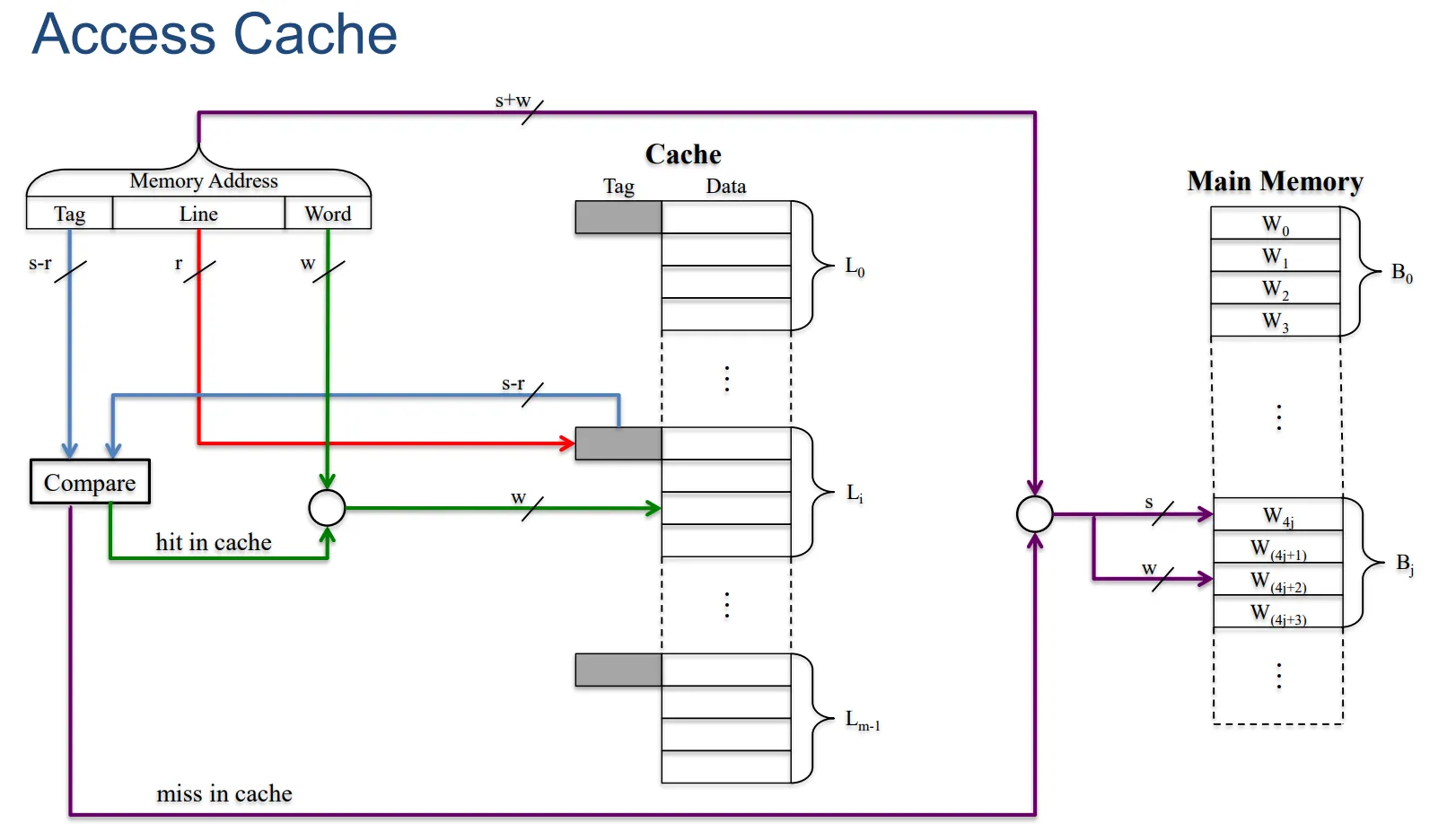
描述一下这个图:Main memory 按照 Cache 进行重新编排,Tag 表示 Main memory 划分为了多少个整个 Cache 大小规模的块,Line 是对一个 Cache 中每一个块的标识,最后 Word 是 Cache 中一个块中的某一个特定的字。
注意:Cache 不同块的 Tag 可能是不同的。
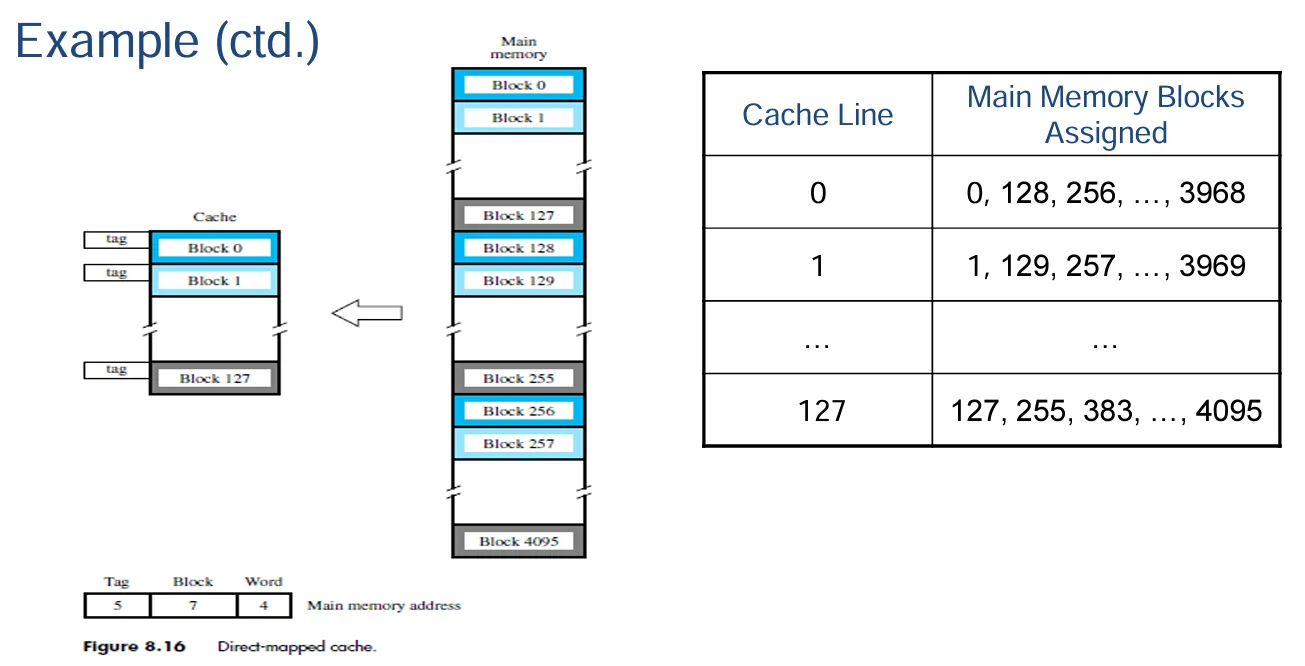
示例说明
- 假设有一个高速缓存,它包含 128 个缓存行,每个缓存行有 16 个字。主存储器有 64K 个字,同时假设主存储器是通过 16 位地址进行寻址的,并且连续的地址指向连续的字。那么,总的主存储器块数量为 64K / 16 = 4K(也就是 4096 个),并且满足关系\(i = j \mod 128\)(即内存块序号 j 对缓存行数量 128 取模等于缓存行序号 i)。
如何将 16 位的地址划分为 Tag, line, word 字段。
- word:\(log_2{16}=4\)。
- line:\(log_2{128}=7\)。
- tag:\(log_2{32}=5\)或者\(16-7-4=5\)。
直接映射的优缺点
- 优点:
- 简单易实现:其原理和实现机制相对比较直观、简单,不需要复杂的逻辑和算法,易于硬件电路去实现这种映射方式。
- 成本低廉:由于结构简单,在硬件设计和制造方面花费的成本相对较低,有助于降低整个系统的成本。
- 缺点:
- 块位置固定:对于给定的内存块,它在高速缓存中的映射位置是固定的。
- 易产生高未命中率:如果一个程序频繁地访问两个映射到同一个缓存行的不同内存块,那么就会反复出现缓存未命中的情况,导致缓存的利用效率降低,影响系统性能。
关联映射(Associative Mapping)的基本特点
- 无映射函数:关联映射不存在像直接映射那样特定的映射函数。主存储器中的一个数据块可以被加载到高速缓存的任意一行当中。
- 主存地址结构:主存地址被解读为标记(Tag)和字(Word)两部分。其中,标记部分占\(s\)位,字部分占\(w\)位,标记能够唯一地标识主存中的数据块。在查找数据时,需要对高速缓存每一行的标记进行检查,看是否与之匹配,不过这样一来,高速缓存的查找操作在硬件实现上成本就比较高了。
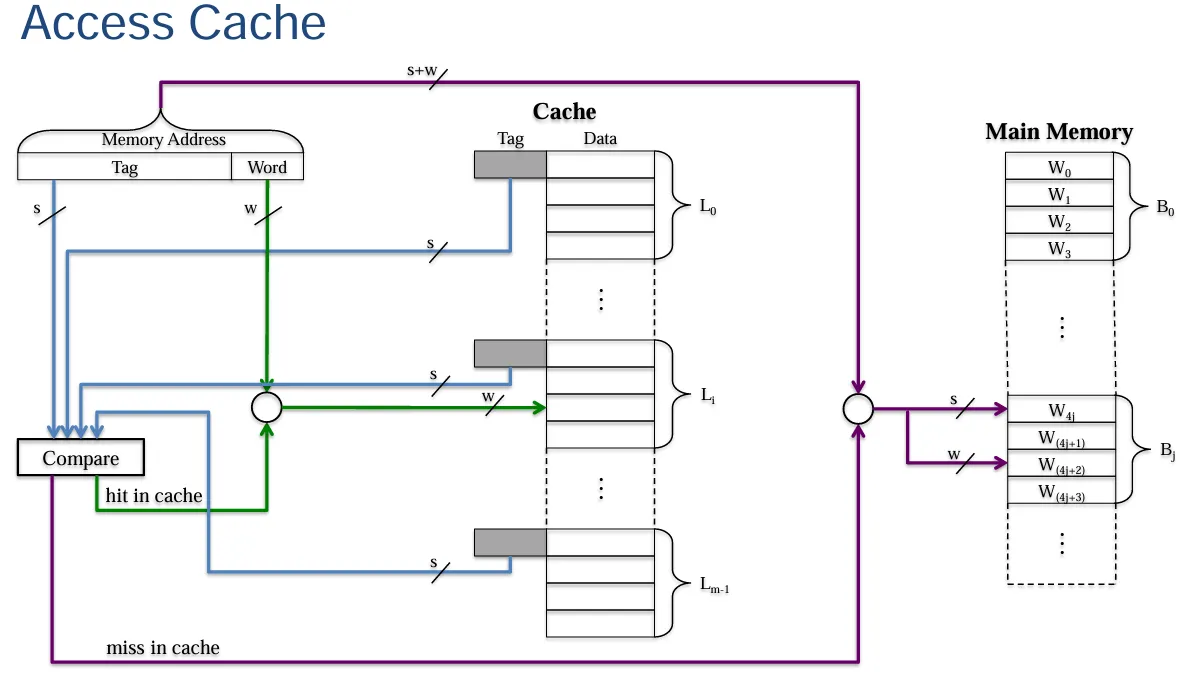
直接比较是主存中的哪一个数据块(Line),随后找字(word)。
示例情况
- 例如,假设有一个包含 128 行的高速缓存,而对应的主存储器有 4096 个数据块。
关联映射的优缺点
- 优点:它赋予了将主存数据块放置到高速缓存位置时完全的自由度,也就是可以根据实际情况灵活选择把数据块存放在高速缓存的哪一行,不受固定映射规则限制。
- 缺点:需要复杂的电路来并行地检查高速缓存中所有数据块的标记,以确定是否命中,这种复杂的硬件电路设计会增加成本,也使得硬件实现的难度提高了。
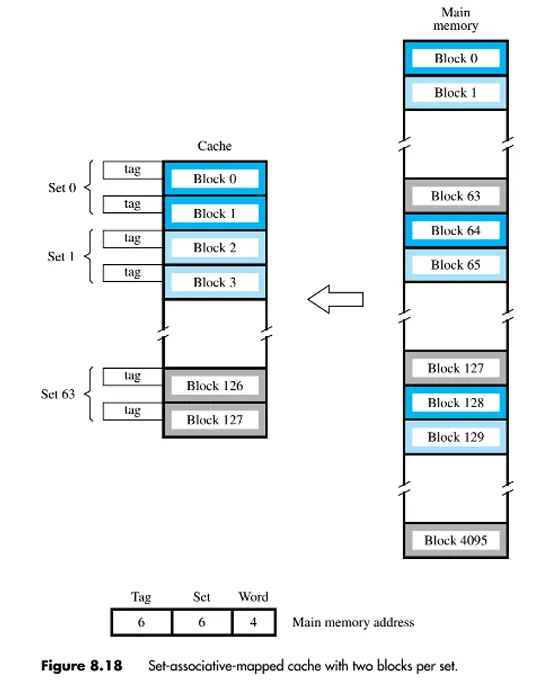
组关联映射(Set Associative Mapping)的基本概念
- 融合两种映射技术:组关联映射是直接映射和关联映射技术的结合体。
- 缓存分组情况:高速缓存会被划分成若干个组,每个组中包含了一定数量的缓存行。
- 块的映射规则:给定的一个主存数据块会映射到某一个给定组内的任意一行中。例如,数据块\(B_j\)可以位于组\(i\)中的任意一行;像每组有 2 行的情况,就是 2-way 组关联映射,意味着一个给定的数据块只能在唯一的一个组内的 2 行之中选择一行进行存放。
组、行数量及映射关系相关说明
- 高速缓存被划分成\(v\)(\(=2^d\))个组,每个组由\(k\)条缓存行组成(也就是\(k\)-way 组关联映射),并且满足\(m = v×k\)。其映射关系通过\(i = j \bmod v\)来确定,这里\(i\)表示高速缓存的组编号,\(j\)表示主存储器数据块的编号,\(v\)就是高速缓存中组的数量。同时还列举了一些特殊情况,比如当\(v = m\),\(k = 1\)时是直接映射;当\(v = 1\),\(k = m\)时是关联映射;当\(v = m/2\),\(k = 2\)时是 2-way 组关联映射;当\(v = m/4\),\(k = 4\)时是 4-way 组关联映射。
主存地址结构说明
- 主存地址结构由标记(Tag)、组(Set)和字(Word)这几部分构成。标记部分占\((s - d)\)位,组字段占\(d\)位,字部分占\(w\)位。其中组字段用于确定高速缓存中的哪个组可能包含所需的数据块。

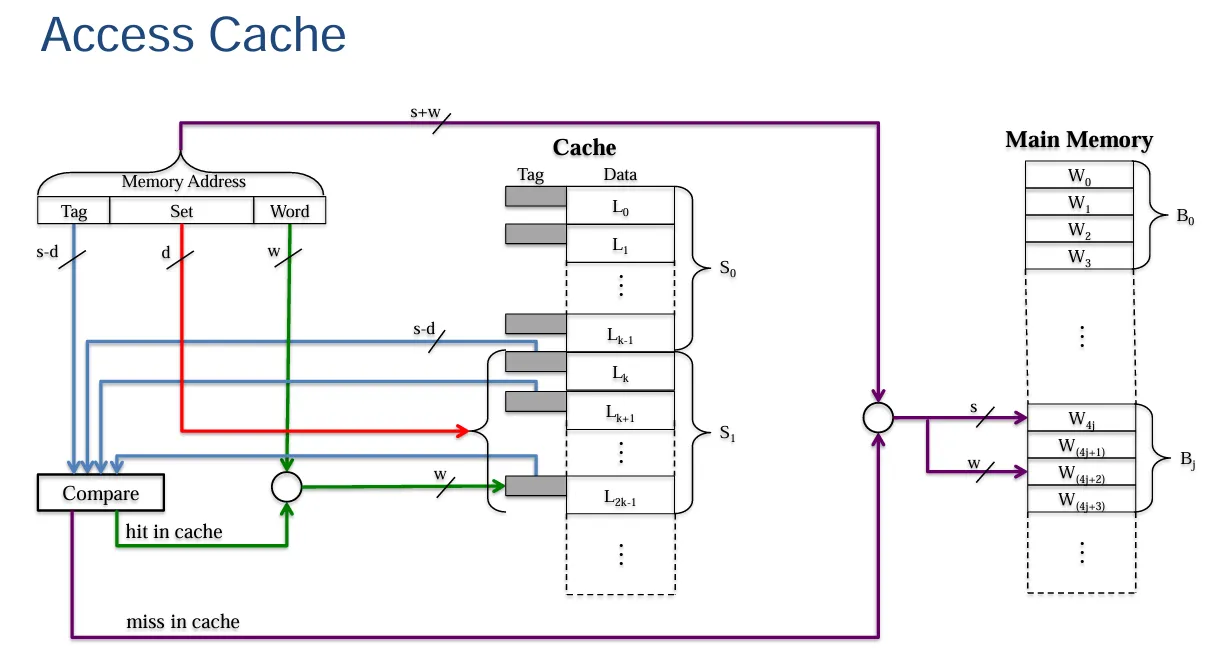
示例情况说明——2-way 组关联映射
在 2-way 组关联映射的示例中,存在映射关系\(i = j \bmod 64\)
如何将 16 位的主存地址划分成标记(Tag)、组(Set)以及字(Word)字段?
- word:\(log_2{16}=4\)
- set:\(log_2{64}=6\)
- Tag:\(16-4-6=6\)。
组关联映射的优缺点
- 优点:
- 缓解块替换的竞争问题:相较于直接映射方法,由于一个数据块在组内有几种可选择的存放位置,在进行块替换时有了更多选择,从而缓解了直接映射中因块位置固定而产生的竞争问题。
- 降低硬件成本:相比于完全关联映射需要对所有缓存行进行关联搜索,组关联映射通过缩小关联搜索的范围(只在组内进行关联搜索),降低了硬件实现上的成本。
- 缺点:
- 需要并行匹配标记:为了判断数据是否存在于高速缓存中,需要对一个组内每个数据块的标记进行并行匹配(需要\(k\)个比较器)。虽然其匹配所需的硬件成本比完全关联映射(需要\(n\)个比较器,\(n\)为数据块数量)要低,但还是比直接映射(只需要一个比较器)要高。
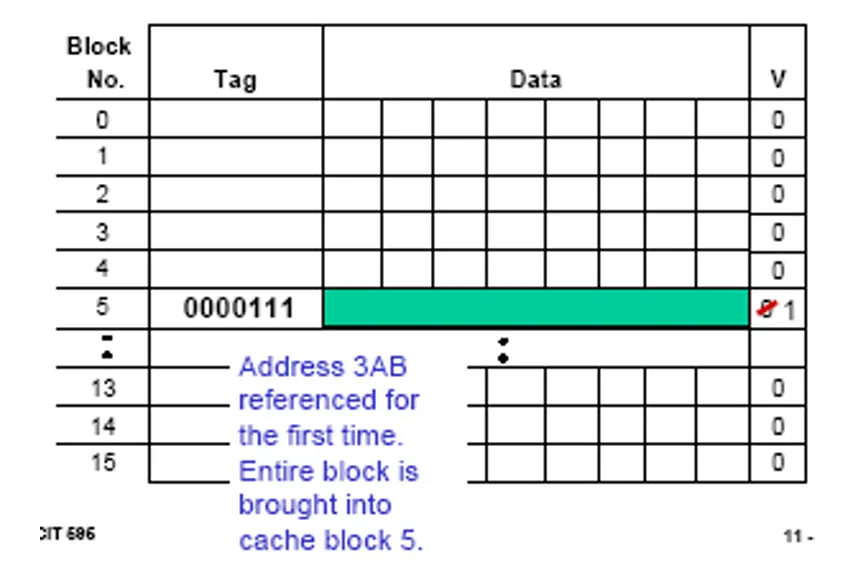
有效位(Valid Bit)
- 初始状态及作用:当系统初次上电时,高速缓存中并不包含有效数据。为此,需要为每个高速缓存块设置一个通常被称作“有效位”的控制位,用它来指示该缓存块中的数据是否有效。
- 有效位取值含义:当有效位取值为0时,表示对应缓存块中的数据无效;取值为1时,则表示数据是有效的。
- 初始设置及更新情况:在系统刚开始通电时,所有高速缓存块的有效位都会被初始设置为 0。而当把主存储器中某个特定块的数据加载到高速缓存相应块后,该缓存块对应的有效位就会被置为 1。下面是一个例子。
替换算法(Replacement Algorithms)
- 直接映射高速缓存(Direct Mapped Cache):
- 替换规则特点:在直接映射高速缓存中没有可选择的余地,因为每个主存储器数据块只映射到唯一的一个高速缓存行。所以当需要替换时,就只能替换掉这个对应的高速缓存行。
- 关联映射和组关联映射高速缓存(Associative and Set
Associative Mapped Cache):
- 算法选择考虑因素:这类高速缓存的替换算法通常由硬件来实现,主要考虑的因素是速度,要能快速地确定替换哪个缓存块。
- 常见替换算法:
- LRU(Least Recently Used,最近最少使用)算法:其核心原则是替换掉长时间未被访问的缓存块,也就是选择那个距离上次被访问时间间隔最长的缓存块进行替换。
- FIFO(First In First Out,先进先出)算法:当一个缓存块被访问时,就把它压入队列,而在需要选择替换块时,则通过弹出队列头部的块来确定要替换的缓存块,遵循先进入队列的先被替换的规则。
- 随机(Random)算法:就是随机选择一个缓存块进行替换,没有特定的规律或依据数据的访问历史等来选择。
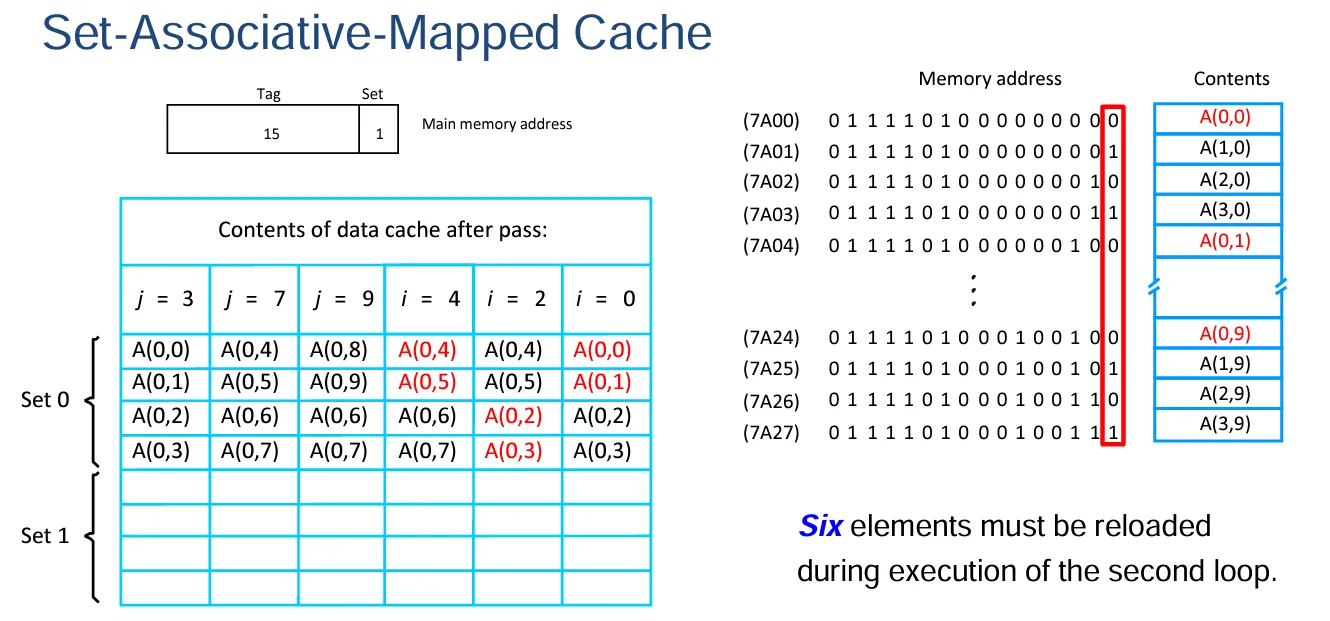
映射技术示例
缓存情况假设:假设处理器具备独立的指令缓存和数据缓存,并且数据缓存仅有能容纳 8 个数据块的空间。每个数据块仅包含一个 16 位的数据字,同时内存是以字为单位进行寻址的,寻址地址为 16 位。
替换算法假设:在该数据缓存中,采用 LRU(最近最少使用)替换算法来进行缓存块的替换操作。
数据存储情况:有一个 4×10 的数字数组,数组中的每个元素都占据一个字的存储空间,这些元素被存储在内存地址从 7A00 到 7A27 的位置。而且该数组 A 的元素是按照列顺序进行存储的。
应用操作情况:相应的应用程序要对数组 A 的第一行元素依据该行元素的平均值进行归一化处理:
$ A(0,i) , for i = 0, 1,2·······9 $
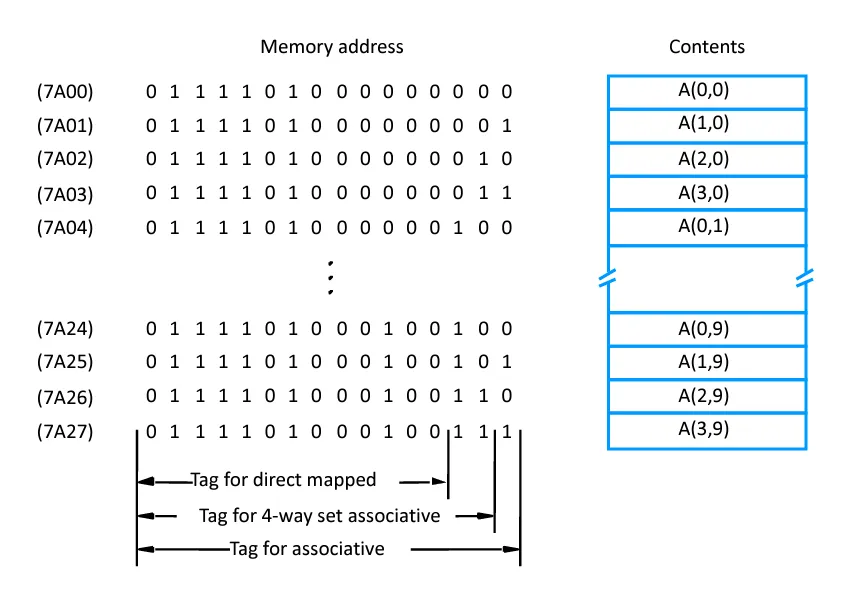
解释一下各种方法的 Tag:
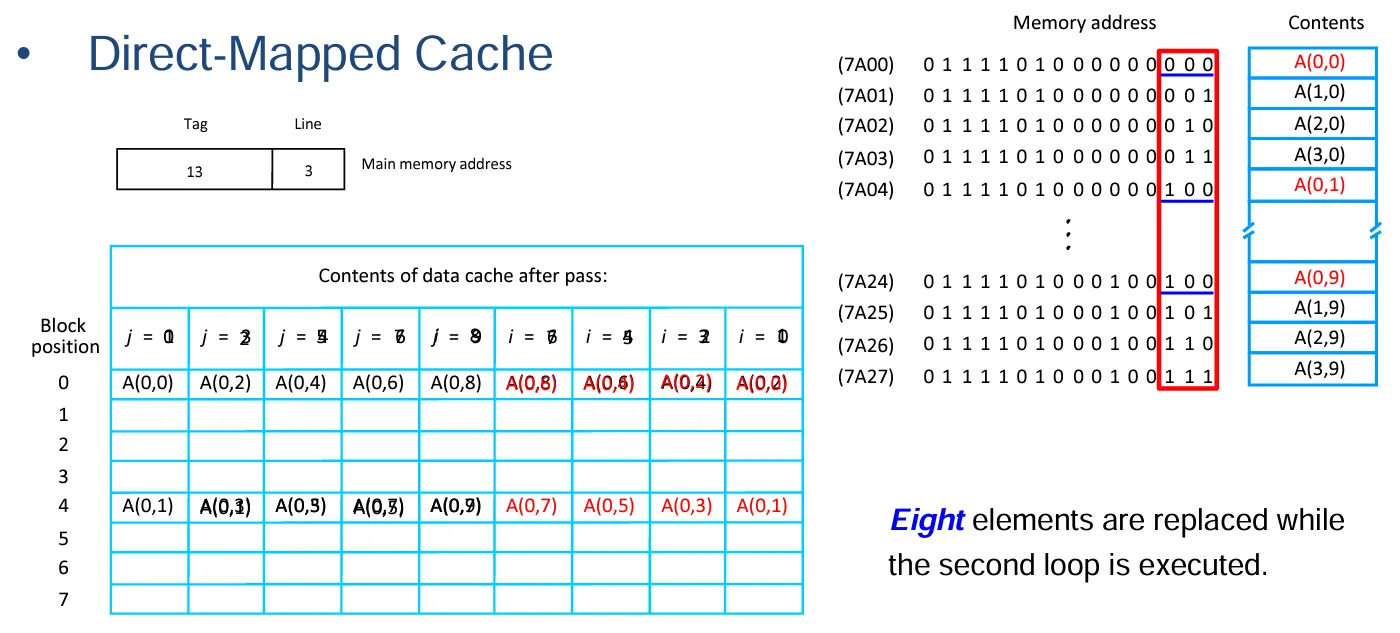
- 直接映射:因为一个块中只有一个字,所以 word 为 0,line 对应的是 8 块数据块,所以是\(16-log_2{8}-0=13\)。
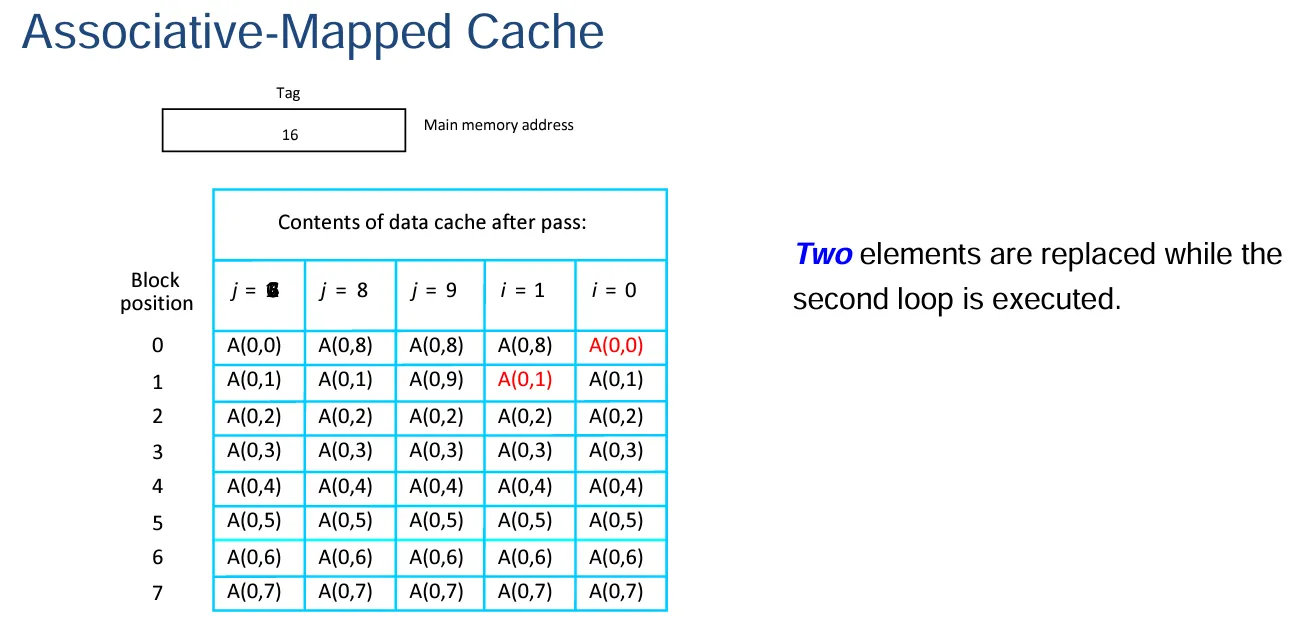
- 关联映射:因为一个块中只有一个字,所以\(word\)为 0,\(16-0=16\)。
- 组相联映射:因为缓存中有 8 块,4 块为一组,所以是两组,有因为一个块中只有一个字,所以\(16-log_2{2}-0=15\)。
sum: = 0 |
直接映射法:
关联映射法:
组相联映射:
写策略
写入命中(Write Hit)——直写(Write Through)方式
- 更新机制:当出现写入命中情况时,采用直写策略意味着会同时更新高速缓存中的相应位置以及主存储器中的对应位置。
- 优点:能够确保高速缓存与主存储器的数据始终保持一致,方便后续的数据访问与操作,维护了数据在不同存储层级间的一致性。
- 缺点:
- 增加主存访问次数:所有的写入操作都需要访问主存储器(涉及总线事务),这无疑增加了对主存的操作频率,也会占用一定的总线资源。
- 拖慢系统速度:倘若因为高速缓存未命中而产生了另一个对主存储器的读请求,那么这个读请求就必须等待之前的写入操作完成后才能进行,从而使得系统整体的运行效率受到影响,出现延迟情况。
写入命中(Write Hit)——回写(Write Back)方式
- 更新机制:在回写策略下,当发生写入命中时,只会更新高速缓存中的相应位置,并且通过设置一个关联的标志位(脏位或修改位)来标记该位置的数据已被更新。只有当包含被标记字的缓存块要从高速缓存中移除时,才会去更新主存储器中对应字的位置。
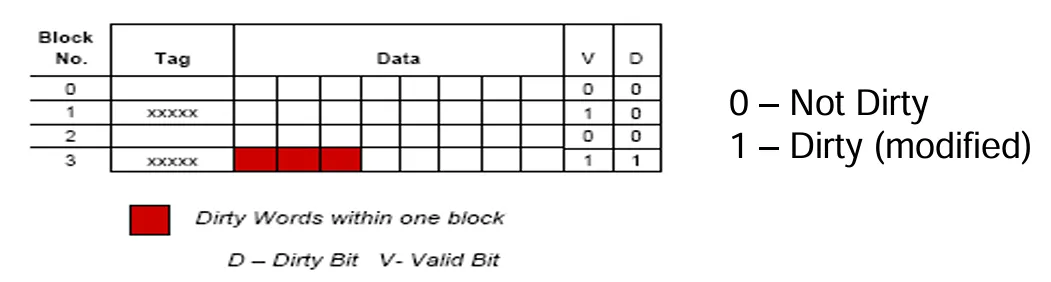
- 优点:
- 速度更快:相比直写方式,它不需要花费时间去立即访问主存储器,减少了写入操作时等待主存响应的时间,能提高写入效率,进而提升系统整体的运行速度。
- 减少主存写入次数:如果是对一个缓存块内的多个字进行写入操作,只需要最后在缓存块移出缓存时对主存储器进行一次写入即可,避免了多次重复写入主存的情况。
- 缺点:
- 主存数据有效性问题:会导致主存储器中的部分数据处于无效状态,这样一来,I/O 模块对主存储器的访问就只能通过高速缓存来进行,增加了访问的复杂性和对缓存的依赖程度。
- 增加缓存空间占用:需要在高速缓存中额外设置一个位来指示哪个缓存块已经被修改过,这无疑会增大高速缓存的空间占用量。
写入未命中(Write Miss)——非写分配(No-Write Allocate)方式
- 处理机制:在采用直写式高速缓存时,如果出现写入未命中的情况,新的信息会直接被写入主存储器中,而不会将相应的数据块加载到高速缓存里面。
写入未命中(Write Miss)——写分配(Write Allocate)方式
- 处理机制:对于回写式高速缓存,当出现写入未命中时,首先会把包含被寻址字的那个数据块先调入高速缓存中,然后再用新的信息覆盖高速缓存中对应的那个字,以此完成写入未命中情况下的操作流程。
命中率与未命中率的定义及计算公式
- 命中率定义及公式:命中次数占所有尝试访问次数的比例被称作命中率。其计算公式为 $ H = ×100% \(,这里\)H\(表示高速缓存的命中率,\)N_c\(是对高速缓存中数据的成功访问次数,\)N_m\(是对主存储器中数据的访问次数,\)N_c + N_m$则为所有尝试访问的总次数。
- 未命中率:相应地,高速缓存的未命中率就是\(1 - H\)。
平均访问时间的计算公式及示例
- 平均访问时间计算公式:平均访问时间\(t_{ave} = Ht_c + (1 - H)t_m\),其中\(t_{ave}\)代表处理器所经历的平均访问时间,\(H\)为高速缓存的命中率,\(t_c\)是访问高速缓存中信息所需的时间,\(t_m\)是访问主存储器中信息所需的时间。
- 示例计算:例如,有访问时间为\(70nsec\)的主存储器以及访问时间为\(10nsec\)的高速缓存,命中率为\(90\%\)。按照公式计算平均访问时间为\(0.9×10 + (1 - 0.9)×70 = 9 + 7 = 16ns\),可以看出这个平均访问时间相比于直接访问主存储器要好得多。
特定计算机的相关参数及未命中惩罚时间计算示例
- 相关参数说明:考虑一台计算机,其高速缓存和主存储器的访问时间分别为\(\tau\)和\(10\tau\)。当发生高速缓存未命中情况时,会有一个包含 8 个字的数据块被传输到高速缓存中。传输这个数据块时,传输第一个字需要花费\(10\tau\),而传输其余 7 个字每个字需要\(\tau\)的时间。并且未命中惩罚还包括最初访问高速缓存(缓存未命中时)的延迟\(\tau\),以及在数据块加载到高速缓存后将字传输给处理器的延迟\(\tau\)。
- 未命中惩罚时间计算:综合上述各项,未命中惩罚时间\(M = \tau + 10\tau + 7\tau + \tau = 19\tau\)。
基于程序指令操作及命中率的缓存作用示例
- 程序相关假设:假设在一个程序中,有\(30\%\)的指令会执行读或写操作(也就是每\(100\)条指令会有\(130\)次内存访问),并且高速缓存中指令的命中率是\(0.95\),数据的命中率是\(0.9\)。
- 缓存作用体现(时间对比):通过计算\(\frac{time\ without\ cache}{time\ with\ cache}\)来体现使用缓存带来的改进,按照所给参数计算可得\(\frac{130×10\tau}{100(0.95\tau + 0.05×19\tau)+30(0.9\tau + 0.1×19\tau)} = 4.7\),说明使用缓存后在时间方面有较为显著的改善效果。
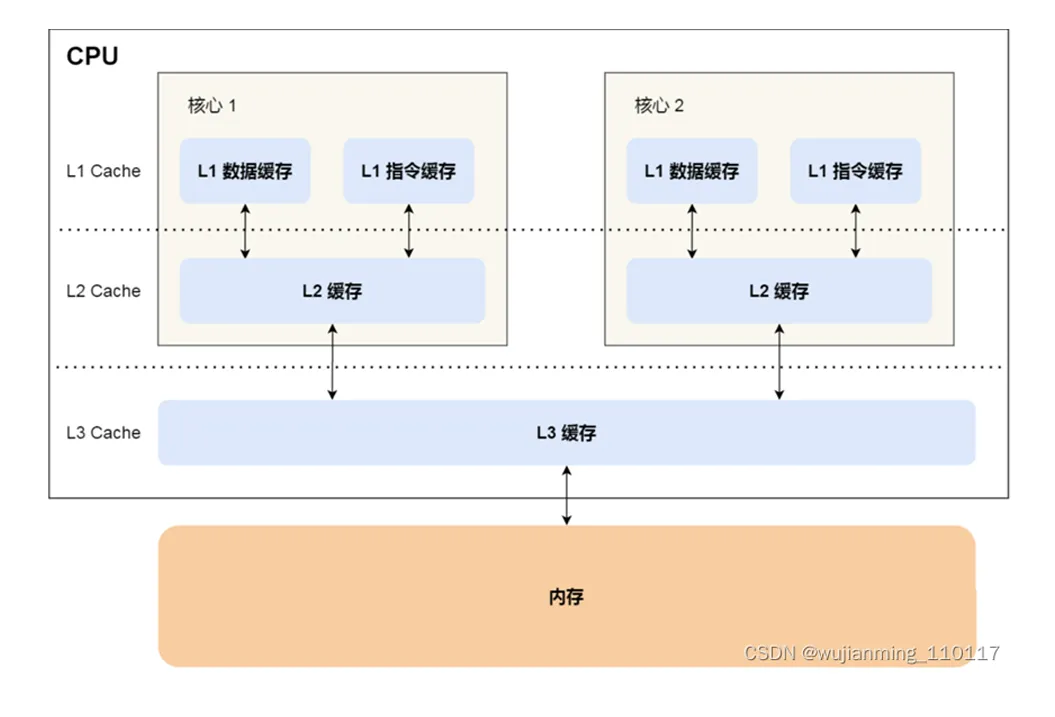
多级缓存层次结构概述
- 多级缓存情况:如今大多数系统都采用多级缓存层次结构,各级缓存自身形成了一个小型的存储层次体系。
- 指令和数据缓存:
- 统一缓存(Unified Cache):是一种将指令和数据都进行缓存的方式,但这种方式容易导致过多的缓存未命中情况出现。
- 分离缓存(Separate Caches):许多现代系统会为数据和指令分别设置缓存,其优势在于能够让访问变得不那么随机,更具聚集性,而且通常比统一缓存的访问时间更短(一般分离缓存的容量会更大些)。
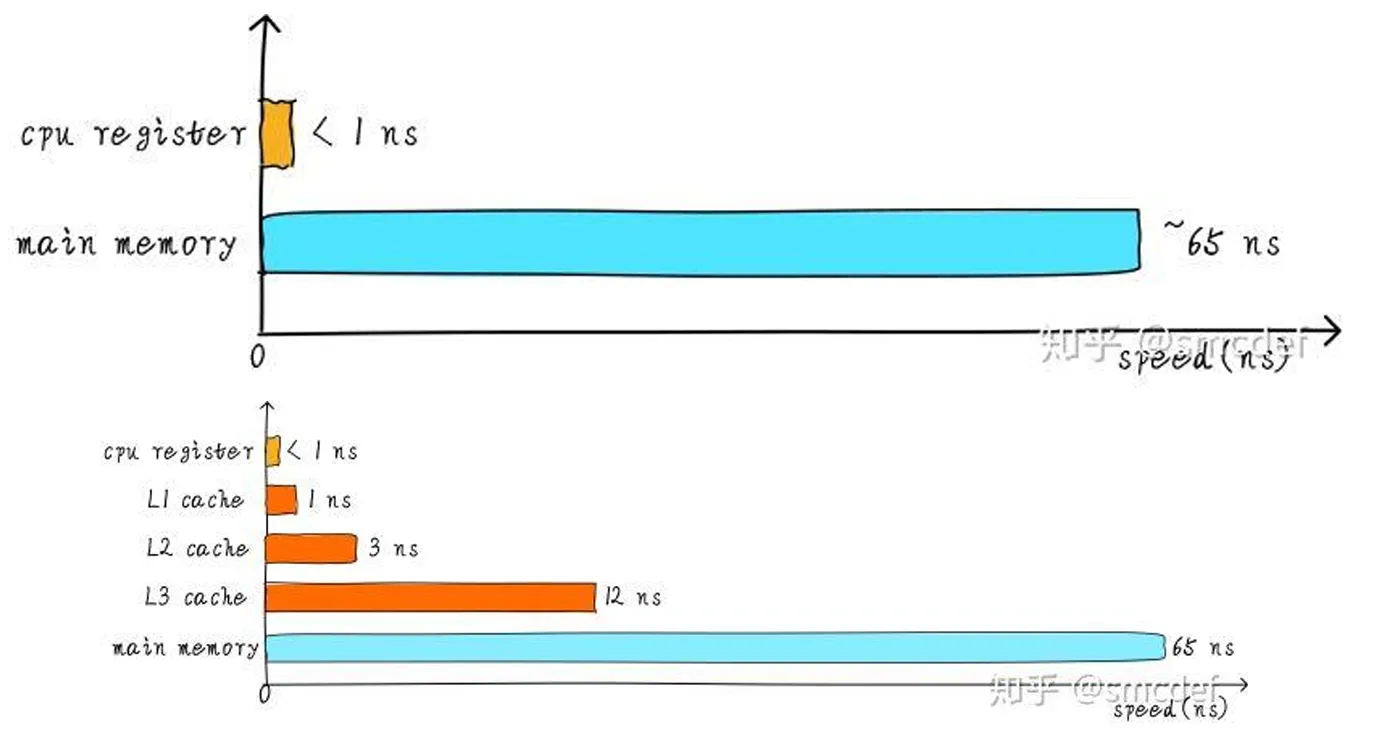
一级缓存(L1)和二级缓存(L2)的特点
- 一级缓存(L1):
- 位置及组成:通常位于 CPU 核心内部,一般是分开设置的(即分为指令缓存和数据缓存)。
- 容量大小:相对比较小,大概在 8KB 到 128KB 之间。
- 访问时间:典型的访问时间大约为 4ns 左右。
- 二级缓存(L2):
- 位置关系:位于 CPU 核心外部。
- 容量特性:比一级缓存大,可能在 256KB 到数 MB 之间。
- 连接与访问时间:通过高速总线与 CPU 相连,访问时间通常在 15 - 20ns 左右,并且一般是统一缓存的形式。
一级缓存和二级缓存的平均访问时间计算公式
平均访问时间\(t_{ave} = h_1C_1 + (1 - h_1)h_2C_2 + (1 - h_2)M\),其中:
- \(h_1\)表示在一级缓存(L1)中的命中率;
- \(h_2\)表示在二级缓存(L2)中的命中率;
- \(C_1\)是访问一级缓存(L1)中信息所需的时间;
- \(C_2\)是将信息从二级缓存(L2)传输到一级缓存(L1)的未命中惩罚时间(即未命中时额外花费的时间);
- \(M\)是将信息从主存储器传输到二级缓存(L2)的未命中惩罚时间。
商业处理器中缓存的示例——英特尔缓存
- 80386 处理器:没有片上缓存,只有外部缓存。
- 80486 处理器:具有片上的一级缓存(L1),容量为 8K,采用 16 字节的缓存行以及 4-way 组关联组织方式;同时还有外部的二级缓存(L2)。
- 奔腾(所有版本)系列处理器:有两个片上的一级缓存(L1),分别用于缓存数据和指令。
- 奔腾 II 处理器:二级缓存(L2)集成在芯片上。
- 奔腾 III 处理器:在芯片外增加了三级缓存(L3)。
商业处理器中缓存的示例(续)——英特尔缓存(续)
- 奔腾 4 处理器:
- 一级缓存(L1):容量在 8K 到 16K 字节之间,缓存行大小为 64 字节,采用 4-way 组关联方式。
- 二级缓存(L2):为两个一级缓存(L1)提供数据支持,容量在 256K 到 512K 字节之间,缓存行大小为 128 字节,采用 8-way 组关联方式,并且还有片上的三级缓存(L3)。
练习
A memory hierarchy _.
A. limits programs' size but allows them to execute more quickly 存储器层次结构不会限制程序大小
B. is a way of structuring memory allocation decisions 存储器层次结构不是一种存储器分配方式
C. takes advantage of the speed of SRAM and the capacity of disk 存储器层次结构利用了 SRAM 的速度和磁盘的容量,给用户造成存储器速度快、容量大的假象
D. makes programs execute more slowly but allows them to be bigger 存储器层次结构使得程序执行得更快
答案:C。
By mapping technique, a main memory block can be placed into any cache block position.
A. direct B. associative C. set associative D. sequential
答案:B。
答案:B. associative
解析:
- 直接映射(Direct Mapping):
- 主存块只能映射到缓存中的一个固定块位置。
- 优点是简单高效,但限制较多。
- 全相联映射(Associative Mapping):
- 主存块可以映射到缓存中的任何位置,即灵活性最高。
- 缓存需要比较所有块的标记位,硬件实现复杂。
- 组相联映射(Set Associative Mapping):
- 主存块只能映射到一个特定组中的任意缓存块。
- 结合了直接映射和全相联映射的优点。
- 顺序映射(Sequential Mapping):
- 此选项并不属于常见的缓存映射技术类型。
正确选项:
根据题意,“主存块可以被放入缓存的任意块位置”,这正是全相联映射(Associative Mapping)的特征。因此,答案是 B. associative。
If a cache has a capacity of 16KB and a line length of 128 bytes, how many sets does the cache have if it is 2-way, 4-way, or 8-way set associative?
A. 64,32,16
B. 64,16,8
C. 32,16,8
D. 128,64,32
答案:A。
cache 包含 16KB/128B=128 个 line
解析:
已知信息:
Cache 总容量:16 KB (\(16 \times 1024 = 16,384\) 字节)
行长度:128 字节
缓存行总数:
\[ \text{缓存行总数} = \frac{\text{总容量}}{\text{行长度}} = \frac{16,384}{128} = 128 \text{ 行} \]
组相联映射: 在组相联缓存中,缓存行被划分为若干组,每组内的缓存行数量称为 相联度(Associativity)。组数(Sets)可以通过以下公式计算:
$$
=
$$
1. 2 路组相联(2-way set associative):
$$
= = 64
$$
2. 4 路组相联(4-way set associative):
$$
= = 32
$$
3. 8 路组相联(8-way set associative):
$$
= = 16
$$
答案:
A. 64, 32, 16
验证:
- 缓存总容量不变,分组数量和相联度关系正确,因此计算合理。 $$
A set-associative cache consists of a total of 64 blocks divided into 4-block sets. The main memory contains 4096 blocks, each consisting of 128 words. How many bits are there in a main memory address?
A. 21 B. 24 C. 19 D. 32
答案:C。
主存有 4096 个块,所以需要 12 位指定块地址;每个块中有 128 个字,所以需要 7 位指定字地址。12+7=19,所以主存地址是 19 位。(无论是哪一种映射法,都是相同的位数)
A set-associative cache consists of a total of 64 blocks divided into 4-block sets. The main memory contains 4096 blocks, each consisting of 128 words. How many bits are there in each of the TAG, SET, and WORD fields?
A. 2,5,12 B. 12,2,5 C. 4,8,7 D. 8,4,7
答案:D。
主存地址总共 19 位,word 部分 7 位,cache 划分为 16 个 set,故 set 部分 4 位,剩下 19-7-4=8 位是 tag 部分。
What are advantages and disadvantages of direct mapping?
Its advantages are:
- Simple, easy to implement
- Inexpensive
Its disadvantage is:
- fixed location for given block
What are advantage and disadvantage of associative mapping?
- Its advantage is that it gives complete freedom in choosing the cache location in which to place the memory blocks.
- Its disadvantage is that it requires complex circuitry to examine the tags of all cache blocks in parallel.
The effectiveness of the cache mechanism is based on a property of computer programs called _.
A. parallelism
C. make the common case fast
B. locality of reference
D. forwarding
答案:B。基于缓存的局部性原理。
中文解释:
答案:B. 局部性原理(locality of reference)
解析:
缓存机制的高效性是基于程序的 局部性原理(Locality of Reference)。局部性是指程序在访问内存时,通常会表现出以下两种特性:
- 时间局部性(Temporal Locality): 如果一个数据在某个时间点被访问过,那么在不久的将来可能会再次被访问。 (例如:循环变量或频繁使用的指令)
- 空间局部性(Spatial Locality): 如果一个数据被访问,那么与其相邻的数据在不久的将来可能会被访问。 (例如:顺序执行的指令或连续的数组元素)
其他选项分析:
- A. 并行性(Parallelism): 与缓存的核心原理无关,更多用于多核处理器的性能提升。
- C. 提高常见情况的效率(Make the common case fast): 虽然是优化原则,但不是缓存机制的直接理论基础。
- D. 转发(Forwarding): 通常是指流水线中的数据转发技术,与缓存机制无关。
结论:
缓存机制的高效性主要依赖程序的 局部性原理,因此答案是 B. locality of reference。
Which of the following manages the transfer of data between the cache and main memory?
A. compiler B. registry C. operating system D. hardware
Cache-主存系统完全由硬件管理
答案:D。
If a cache has 64-byte cache lines, it takes cycles to fetch a cache line if the main memory takes 20 cycles to respond to each memory request and returns 2 bytes of data in response to each request.
A. 128 B. 320 C. 640 D. 256
答案:C。
(64/2)*20=640
In cache system, when a block is to be overwritten, it is sensible to overwrite the one that has gone the longest time without being referenced. This technique is called the replacement algorithm.
A. FIFO B. Random C. LFU D. LRU
答案:D。
替换掉最长时间没有被访问过的块,是最近最少使用算法(LRU)的替换原则
True or False? In a direct-mapped cache, it is sensible to use Random replacement policy when a line must be evicted from the cache to make room for incoming data.
In direct-mapped caches, there is no choice about which line to evict, since the incoming line can only be placed in one location in the cache.
True or False? For a Write operation, the cache location and the main memory are updated simultaneously. This technique is called the write-through protocol.
答案:True
解析:
在写操作(Write Operation)中,如果缓存中的数据和主存的数据同时更新,这种技术被称为 写直达协议(Write-Through Protocol)。
特点:
- 数据一致性:
- 写操作立即将数据写入主存,保证主存和缓存中的数据始终一致。
- 不容易出现主存与缓存不同步的情况。
- 缺点:
- 每次写操作都会访问主存,写操作的延迟会比较高,因此性能较低。
对比:Write-Back Protocol
- 写操作只更新缓存,而主存只有在缓存行被替换(evicted)时才更新。性能较高,但需要更多的管理机制以保证一致性。
结论:
该描述是正确的,写直达协议的定义符合题意,因此答案是 True。
What are advantages and disadvantages of write through policy?
Advantage: Keeps cache main memory consistent at the same time.
Disadvantages:
- All writes require main memory access (bus transaction).
- Slows down the system - If the there is another read request for main memory due to miss in cache, the read request has to wait until the earlier write was serviced.
What are advantages and disadvantages of write back policy?
Advantages:
- (1)Faster than write-through, time is not spent accessing main memory.
- (2)Writes to multiple words within a block require only one write to the main-memory.
Disadvantages:
- (1)Portions of main memory are invalid, and hence accesses by I/O modules can be allowed only through the cache.
- (2)Need extra bit in cache to indicate which block has been modified. Adds to size of the cache.





